如何在CentOS系统中激活网络连接?

CentOS 网络激活详解
在CentOS系统中,网络连接的激活和管理是系统管理员的基本技能之一,无论是在服务器环境下还是在桌面应用中,确保网络接口的正确配置和激活都是至关重要的,本文将详细介绍如何在CentOS中激活网络连接,涵盖从检查网卡状态到编辑配置文件、使用NetworkManager以及解决常见问题的多个方面。
一、检查当前网络接口状态
在开始任何网络配置之前,首先需要了解当前系统中的网络接口状态,打开终端并输入以下命令:
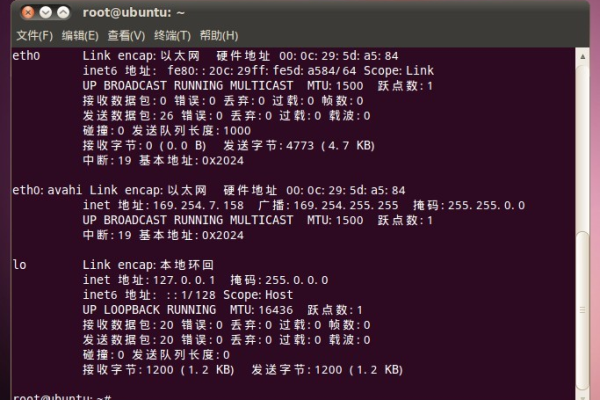
ifconfig -a
此命令将列出所有网络接口及其状态,常见的网络接口名称包括eth0、ens33 等,找到你需要配置的接口,例如eth0。
二、编辑网络配置文件
CentOS7及更高版本主要采用NetworkManager 和network-scripts 来管理网络,以下是通过修改配置文件来激活网络连接的步骤。
1、使用nmcli 命令(如果使用 NetworkManager)
如果你的系统使用 NetworkManager 来管理网络,可以使用nmcli 命令来激活特定的网络接口,假设你要激活的是eth0,输入以下命令:
nmcli con up eth0
如果接口名称不同,请相应替换。
2、编辑 ifcfg 文件
如果不使用 NetworkManager,或者需要更详细的配置,可以手动编辑 ifcfg 文件,这些文件通常位于/etc/sysconfig/network-scripts/ 目录下,以ifcfg-ethX 格式命名。
使用文本编辑器打开对应的配置文件,例如ifcfg-eth0:

sudo vi /etc/sysconfig/network-scripts/ifcfg-eth0
确保文件中包含以下关键参数:
BOOTPROTO=static ONBOOT=yes IPADDR=192.168.1.100 # 你的静态IP地址 NETMASK=255.255.255.0 # 子网掩码 GATEWAY=192.168.1.1 # 网关地址 DNS1=8.8.8.8 # 主DNS服务器地址 DNS2=8.8.4.4 # 备用DNS服务器地址
保存并关闭文件后,重启网络服务以应用更改:
sudo systemctl restart network
三、使用 NetworkManager GUI 工具
对于桌面用户,可以使用 NetworkManager 提供的图形界面工具来进行网络配置:
1、点击屏幕右上角的网络图标。
2、选择“编辑连接”。
3、在列表中选择要编辑的连接,点击“编辑”。
4、在“IPv4 设置”标签下,可以选择“自动(DHCP)”或“手动”,并根据需要填写详细信息。

5、保存并激活连接。
四、常见问题及解决方案
1、网卡驱动问题:确保系统中已安装正确的网卡驱动,可以使用以下命令检查:
lsmod | grep ethernet
如果没有列出相应的驱动模块,可能需要手动下载并安装。
2、防火墙设置:防火墙可能会阻止网络连接,使用以下命令查看防火墙状态:
sudo systemctl status firewalld
如果防火墙正在运行,可以使用以下命令允许特定端口的流量:
sudo firewall-cmd --zone=public --add-port=<port_number>/tcp --permanent sudo firewall-cmd --reload
3、VMware 虚拟机中的网络问题:如果在 VMware 虚拟机中遇到网络连接问题,可以尝试以下步骤:
确保 VMware DHCP Service 已启动,在 Windows 主机上,按Win+R,输入services.msc,找到 VMware DHCP Service,确保其已启动。
在 VMware 中,打开虚拟网络编辑器,确保网络适配器设置为桥接模式或其他适当的模式。
在虚拟机设置中,确保网络适配器已连接到正确的虚拟网络。

通过以上步骤,你应该能够在 CentOS 系统中成功激活和管理网络连接,无论是通过命令行工具还是图形界面工具,掌握这些基本操作将帮助你更好地配置和维护 CentOS 系统的网络环境,如果在实际操作中遇到问题,建议逐步排查,从网卡驱动、配置文件到防火墙设置等多个方面进行检查和调整。
六、相关问答FAQs
Q1: 如果网络接口未激活怎么办?
A1: 如果网络接口未激活,可以尝试使用以下命令手动激活:
sudo ifup eth0
请将eth0 替换为实际的网络接口名称,如果仍然无法激活,请检查配置文件和日志信息以获取更多错误细节。
Q2: 如何更改 CentOS 中的默认网关地址?
A2: 可以通过编辑 ifcfg 文件来更改默认网关地址,打开对应的 ifcfg 文件,例如ifcfg-eth0,然后添加或修改GATEWAY 参数:
GATEWAY=192.168.1.1
保存文件后,重启网络服务以应用更改:
sudo systemctl restart network


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

配件网站模板_网站模板设置
2024-06-23 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20