如何查询企业邮箱的编号?

企业邮箱编号通常由企业内部的IT部门或邮件服务提供商分配,用于标识和管理员工的电子邮箱。具体编号规则可能因企业而异,无法直接提供。
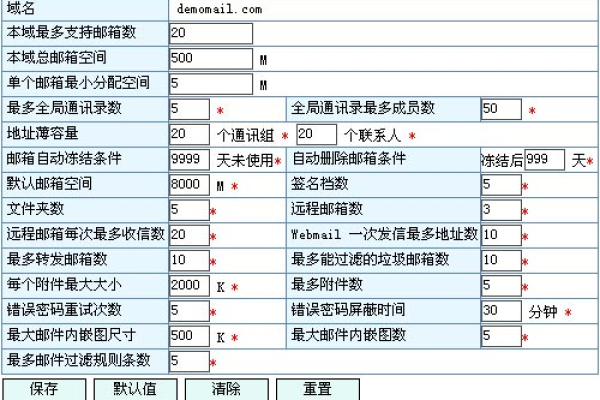
企业邮箱编号是企业在电子邮件系统中为员工分配的唯一标识符,用于区分不同员工的邮箱地址,企业邮箱编号通常由字母和数字组成,长度和格式可能因企业而异,以下是一些常见的企业邮箱编号格式:
用户名@公司域名.com
username_companyname@domain.com
employeeid@company.com

企业邮箱编号的设置有助于提高企业内部沟通效率,确保邮件发送的准确性和安全性,企业邮箱编号也可以作为员工身份的标识,方便企业进行人员管理和权限控制。
在实际应用中,企业邮箱编号的设置和管理需要遵循一定的规范和流程,以下是一些建议:
1、统一规划:企业在设置邮箱编号时,应遵循统一的规划和标准,确保邮箱编号的一致性和可识别性。
2、易于记忆:邮箱编号应尽量简洁明了,便于员工记忆和使用,可以使用员工的姓名、工号等信息作为邮箱编号的一部分。

3、安全性:为了保障企业邮箱的安全,应设置复杂的密码策略,定期更换密码,并对敏感信息进行加密处理。
4、灵活性:企业邮箱编号应根据企业的实际需求进行调整和优化,以适应企业发展和变化。
5、培训与宣传:企业应对员工进行邮箱使用培训,提高员工的邮箱使用技能和安全意识,通过内部宣传,让员工了解企业邮箱编号的重要性和使用方法。

6、技术支持:企业应提供邮箱技术支持服务,解决员工在使用企业邮箱过程中遇到的问题,确保企业邮箱的正常运行。
企业邮箱编号是企业内部沟通和管理的重要工具,企业应重视邮箱编号的设置和管理,提高企业内部沟通效率,保障企业信息安全。
小伙伴们,上文介绍了“企业邮箱编号是多少”的内容,你了解清楚吗?希望对你有所帮助,任何问题可以给我留言,让我们下期再见吧。




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20