如何在Maven中配置多个项目设置?

pom.xml 文件中配置多个 “ 元素。
在Maven项目中,配置多个镜像和仓库是常见的需求,特别是在国内访问官方Maven仓库速度较慢的情况下,以下是详细的配置指南:
配置镜像仓库
1、打开配置文件:找到Maven的配置文件settings.xml,通常位于Maven安装目录的conf文件夹下。
2、添加镜像节点:在<mirrors>标签中添加mirror子节点,用于配置镜像仓库,可以添加阿里云的镜像仓库作为中央仓库的镜像:
<mirror>
<id>aliyun</id>
<mirrorOf>central</mirrorOf>
<name>aliyun</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
3、配置多个镜像:如果需要配置多个镜像,可以在<mirrors>标签下添加多个mirror子节点,但需要注意的是,Maven默认只会使用第一个镜像,只有当第一个镜像不可用时,才会尝试使用后面的镜像。

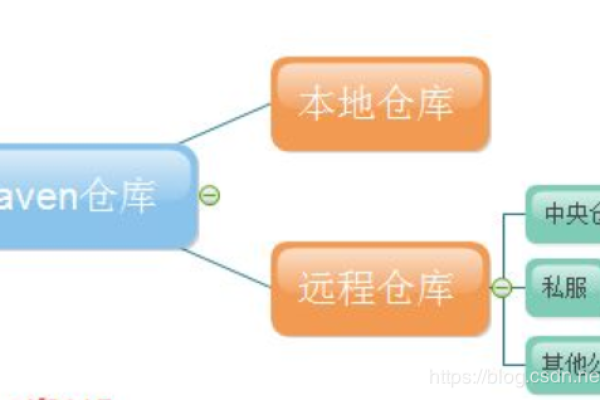
配置私有仓库
1、在profiles标签中配置:在<profiles>标签中添加profile子节点,用于配置私有仓库,每个profile可以包含一个或多个repository子节点,用于定义私有仓库的信息。
2、示例配置:
<profile>
<id>gf</id>
<repositories>
<repository>
<id>mavendefault</id>
<url>http://repo1.maven.org/maven2/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
</snapshots>
</repository>
</repositories>
</profile>
3、激活profile:在<activeProfiles>标签中添加需要激活的profile的ID,以激活相应的私有仓库配置。
<activeProfiles>
<activeProfile>aliyun</activeProfile>
<activeProfile>gf</activeProfile>
</activeProfiles>
注意事项
1、镜像仓库与私有仓库的区别:镜像仓库是远程仓库的镜像,用于加速依赖的下载;而私有仓库则是存放项目特定依赖的地方,在配置时需要注意区分两者的作用和用途。

2、版本控制:在配置私有仓库时,可能需要根据项目的需求设置不同的版本控制策略,如快照版本的更新策略等。
3、冲突解决:如果多个仓库中存在相同的依赖但版本不同,Maven会根据其内部规则选择一个版本进行下载,在配置多个仓库时需要注意避免版本冲突的问题。
通过以上步骤和示例配置,你可以在Maven中配置多个镜像仓库和私有仓库,以满足项目的需求并提高构建效率。

下面是一个使用归纳来展示 Maven 中多个配置的示例:
| 配置项 | 说明 | 示例值 |
pom.xml |
Maven 的项目对象模型(Project Object Model)文件,定义了项目的配置信息 | “
“ |
groupId |
项目组织标识符 | com.example |
artifactId |
项目名称 | myproject |
version |
项目版本号 | 1.0.0SNAPSHOT |
packaging |
项目打包类型 | jar,war,pom 等 |
dependencies |
项目依赖列表 | “
“ |
dependency |
单个依赖配置 | “
“ |
dependencyManagement |
依赖管理配置,用于统一管理依赖的版本 | “
“ |
properties |
项目属性配置 | “
“ |
build |
项目构建配置 | “
“ |
plugins |
项目构建插件配置 | “
“ |
plugin |
单个插件配置 | “
“ |
sourceDirectory |
源代码目录 | src/main/java |
outputDirectory |
输出目录 | target/classes |
resources |
资源目录 | src/main/resources |
testSourceDirectory |
测试源代码目录 | src/test/java |
testResources |
测试资源目录 | src/test/resources |
maven.compiler.source |
指定编译源代码的版本 | 1.8 |
maven.compiler.target |
指定编译生成的字节码版本 | 1.8 |
这个归纳展示了 Maven 中一些常见的配置项及其用途和示例值,在实际的项目中,可能需要根据具体需求调整这些配置。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01