Windows7系统扬声器音量图标不见了怎么找回

在Windows 7操作系统中,音量图标通常位于任务栏的通知区域,如果发现扬声器的音量图标不见了,可能会对调整系统声音造成不便,以下是一些步骤和方法来帮助找回丢失的音量图标。
检查音量图标设置
我们需要确认音量图标是否被隐藏或禁用。
1、右键点击任务栏的空白处,选择“属性”。
2、在“任务栏和开始菜单属性”窗口中,点击“自定义”按钮。
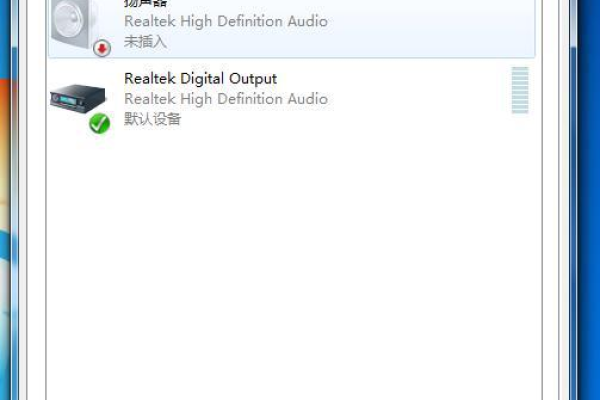
3、在“通知区域图标”窗口中,找到“音量”图标,确保其行为设置为“显示图标和通知”。
如果音量图标被设置为“仅显示通知”或“隐藏图标和通知”,那么它可能不会显示在任务栏上。
重启音频服务
音量图标不见可能是由于音频服务没有正常运行导致的。
1、按下Win + R键打开运行对话框,输入services.msc并回车。

2、在服务列表中找到“Windows Audio”服务,右键点击它,选择“重新启动”。
这样可以尝试恢复音频服务的正常运行,从而让音量图标重新出现。
更新或重新安装音频驱动
驱动程序的问题也可能导致音量图标消失。
1、打开“设备管理器”,找到“声音、视频和游戏控制器”并展开。
2、右键点击音频设备的驱动程序,选择“更新驱动程序”尝试自动搜索更新。
3、如果更新不成功,可以选择“卸载设备”,然后重启计算机让系统自动重新安装驱动程序。

使用系统还原
如果以上方法都不能解决问题,可以考虑使用系统还原功能恢复到音量图标消失之前的状态。
1、在控制面板中搜索“系统还原”,打开系统还原功能。
2、选择一个合适的还原点,通常是最近一个创建的还原点,然后执行还原操作。
检查系统文件完整性
系统文件损坏也可能导致音量图标消失。
1、打开命令提示符(以管理员身份),输入sfc /scannow命令来扫描修复系统文件。

相关问答FAQs
Q1: 如果音量图标和音频服务都正常,但仍然无法调节音量怎么办?
A1: 如果音量图标可见且音频服务运行正常,但无法调节音量,可能是系统设置问题,请检查是否不小心将音量调至最低或静音,检查是否有第三方软件控制了音量设置,如某些音频增强软件可能会接管系统音量控制。
Q2: 音量图标不见了,但是有声音输出,需要担心吗?
A2: 如果系统有声音输出,说明音频硬件和驱动程序基本上是正常工作的,音量图标不见更多是系统设置或界面显示问题,虽然不影响实际的声音输出,但为了方便调节音量,还是建议按照上述步骤尝试恢复音量图标的显示。
通过上述步骤,大多数情况下可以解决Windows 7系统中音量图标消失的问题,如果问题依旧存在,可能需要进一步检查系统是否存在其他深层次的问题。






热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01