如何在MySQL数据库中一次性添加多条数据?

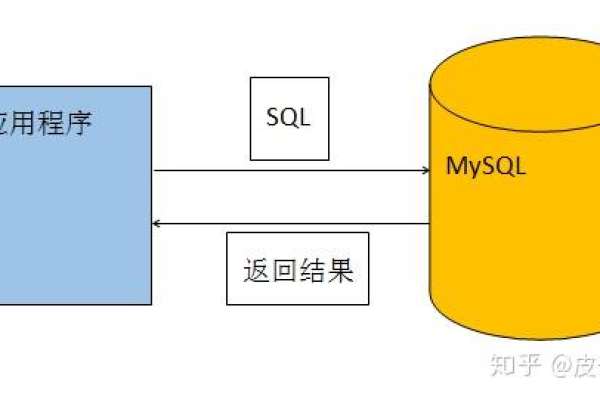
在MySQL数据库中,可以使用
INSERT INTO 语句一次性添加多条数据。,,“
sql,INSERT INTO table_name (column1, column2, column3),VALUES , (value1a, value2a, value3a),, (value1b, value2b, value3b),, (value1c, value2c, value3c);,“,,这样可以同时插入多行数据,提高操作效率。
在MySQL数据库中添加多条数据可以通过一条INSERT语句实现,以下是详细步骤和示例:
基本语法
使用单条INSERT语句插入多条数据的语法格式如下:
INSERT INTO table_name (column1, column2, ...) VALUES (value1a, value1b, ...), (value2a, value2b, ...), ...;
示例
假设有一个名为students的表,结构如下:
| id | name | age | gender | class | address |
|||||||

现在需要一次性向该表中插入多条记录,可以使用以下SQL语句:
INSERT INTO students (name, age, gender, class, address)
VALUES
('Alice', 18, 'Female', 'Class A', '123 Main St'),
('Bob', 19, 'Male', 'Class B', '456 Elm St'),
('Charlie', 20, 'Male', 'Class C', '789 Oak St');
在这个例子中,通过一次INSERT语句,同时插入了三条学生信息到students表中。
优点
1、减少数据库连接次数:使用单条INSERT语句插入多条数据可以减少与数据库建立连接的次数,从而降低服务器负荷。
2、提高插入效率:批量插入数据可以减少网络延迟和磁盘I/O,提高整体数据插入效率。
注意事项
列数和顺序:确保每个VALUES子句中的值数量和顺序与列名列表一致。
数据量限制:虽然批量插入效率高,但也要注意单次插入的数据量,避免过大的数据量导致性能问题。
通过使用单条INSERT语句插入多条数据,可以显著提高数据插入效率,减少数据库连接次数,这种方法在处理大量数据时尤为有效,是优化数据库操作的重要手段之一。
下面是一个归纳示例,展示了如何使用MySQL语句向数据库中的表添加多条数据,我们将假设有一个名为employees的表,它具有以下列:id(主键),name(员工姓名),department(部门)和salary(薪资)。
| 语句 | 说明 |
“INSERT INTO employees (name, department, salary) VALUES ('Alice', 'HR', 50000);` |
向employees`表添加一条记录,名为Alice,在HR部门,薪资为50000。 |
“INSERT INTO employees (name, department, salary) VALUES ('Bob', 'Engineering', 60000);` |
向employees`表添加一条记录,名为Bob,在Engineering部门,薪资为60000。 |
“INSERT INTO employees (name, department, salary) VALUES ('Charlie', 'Marketing', 55000);` |
向employees`表添加一条记录,名为Charlie,在Marketing部门,薪资为55000。 |
“INSERT INTO employees (name, department, salary) VALUES ('David', 'Sales', 70000);` |
向employees`表添加一条记录,名为David,在Sales部门,薪资为70000。 |
这些语句应该在一个支持SQL的MySQL客户端中执行,例如MySQL Workbench、phpMyAdmin或其他任何支持MySQL的IDE或命令行工具,如果你要一次性添加多条记录,也可以使用以下格式:
INSERT INTO employees (name, department, salary) VALUES
('Alice', 'HR', 50000),
('Bob', 'Engineering', 60000),
('Charlie', 'Marketing', 55000),
('David', 'Sales', 70000);
这将会一次性向employees表中插入四条记录。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01