是否可以对.red域名进行备案?

.red域名备案
所有希望在境内提供服务的网站都需要进行icp备案,icp备案是指在中国工业和信息化部(miit)进行的官方登记,以获得在中国境内合法运营网站的资格,这个过程涉及到提供网站所有者的详细信息、网站内容和服务提供商信息等。
对于特殊顶级域名(slds),如.red,是否可以备案取决于多种因素,包括域名后缀是否被中国工信部认可以及注册该域名的注册商是否支持中国备案流程。
备案条件
1. 域名后缀的认可情况
工信部会定期更新可备案的顶级域列表,red顶级域被列入了工信部认可的名单中,那么使用.red域名的网站就可以进行icp备案。
2. 注册商的支持
即使.red域名被工信部认可,还必须确保你的域名注册商支持.cn的icp备案流程,不是所有的注册商都提供备案服务,因此需要事先确认。
3. 资料准备
有效的身份证明或企业资质证明文件;
域名证书;
网站负责人信息;
网站服务内容说明;
服务器提供商信息。
4. 审核过程
提交备案申请后,工信部会对提供的资料进行审核,这通常需要一段时间,审核通过后,网站方可在中国内地提供服务。
实际操作步骤
1. 检查域名后缀是否被认可
访问工信部官网或咨询注册商,查看.red是否在最新的可备案列表中。
2. 选择支持备案的注册商
如果你的.red域名尚未注册,选择一个支持备案的注册商进行注册,如果已注册,需确认当前注册商是否支持备案流程。
3. 准备备案资料
根据工信部的要求准备相应的备案文件和资料。
4. 提交备案申请
通过注册商或直接在工信部网站提交备案申请,并等待审核。
5. 完成备案
一旦审核通过,你的.red域名就完成了在中国的icp备案流程,可以合法地在中国内地提供服务。
相关问题与解答
q1: red域名不能备案怎么办?
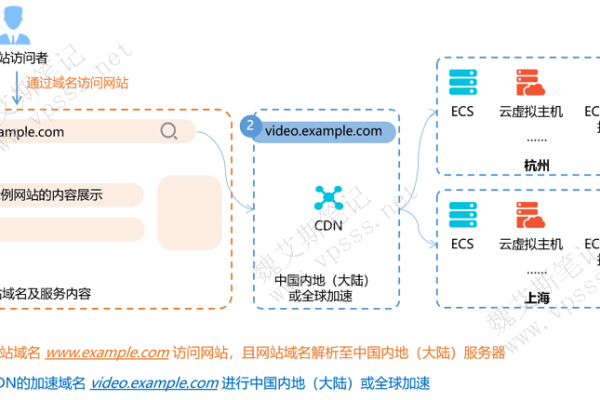
a1: red域名不能备案,你将无法在中国内地合法地提供服务,可以考虑使用其他被工信部认可的顶级域名进行备案,或者将网站服务器放置在中国境外,并通过cdn等方式向中国内地用户提供服务。
q2: 备案过程中遇到问题应该如何解决?
a2: 如果在备案过程中遇到任何问题,首先应联系你的域名注册商获取帮助,注册商通常有专门的备案团队来指导客户完成备案流程,若问题仍未解决,可以直接咨询工信部相关部门或寻求专业的法律顾问协助。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/68206.html