ASP.NET的用途及其在实际项目中的应用场景是什么?

ASP.NET是一种功能强大的服务器端Web应用程序开发框架,由微软公司开发和维护,它广泛应用于各种类型的Web应用程序开发中,包括但不限于以下几个方面:
1、企业级应用:
ASP.NET常用于构建大型企业级应用,如客户关系管理系统(CRM)、企业资源规划系统(ERP)和人力资源管理系统(HRM),这些系统需要处理大量数据和复杂的业务逻辑,ASP.NET提供了强大的功能来满足这些需求。
2、电子商务网站:
许多电子商务网站使用ASP.NET来构建其在线商店和购物车功能,ASP.NET可以处理交易、库存管理、支付集成等关键功能,确保网站的高效运行。
3、社交媒体平台:
一些社交媒体平台和社交网络使用ASP.NET来支持用户注册、个人资料管理、信息流和社交互动功能,ASP.NET的可扩展性和安全性使其成为构建这些应用的理想选择。
4、内容管理系统(CMS):
许多网站使用ASP.NET开发的CMS来管理和发布内容,这些系统允许用户创建、编辑和发布网站上的内容,而无需深入了解编程,ASP.NET提供了丰富的工具和库来简化CMS的开发。

5、在线学习平台:
在线学习平台使用ASP.NET来提供课程管理、学习资源管理、在线考试和学员交互功能,ASP.NET的安全性和易用性使其成为构建这些教育应用的理想选择。
6、医疗保健应用程序:
医疗保健行业使用ASP.NET构建电子健康记录(EHR)系统、医疗预约平台和医疗数据管理应用程序,以提高患者护理的效率和质量。
7、金融和银行应用程序:
金融和银行领域使用ASP.NET构建在线银行系统、投资管理应用程序、支付处理和财务分析工具,ASP.NET的安全性和稳定性对于处理敏感的金融数据至关重要。

8、游戏开发:
ASP.NET可以用于创建在线多人游戏服务器,支持实时游戏互动和多人游戏管理,它的高性能和可扩展性使其成为游戏开发者的首选框架之一。
9、政府和公共服务:
政府和公共机构使用ASP.NET来开发在线服务、电子政府平台、税务系统等,以提供更方便的公共服务。
10、移动应用后端:
ASP.NET可以用于构建移动应用程序的后端API,以支持移动应用与服务器之间的数据交换和通信。

11、云计算:
ASP.NET Core是一个跨平台的Web应用程序框架,适用于云计算环境,可轻松部署到云平台上。
12、物联网(IoT)应用程序:
ASP.NET可用于开发IoT应用程序的后端,以收集和分析传感器数据。
ASP.NET以其强大的功能、灵活性和广泛的应用场景,在Web开发领域占据着重要的地位,无论是企业级应用、电子商务网站还是其他类型的Web应用,ASP.NET都能提供高效、可靠的解决方案。

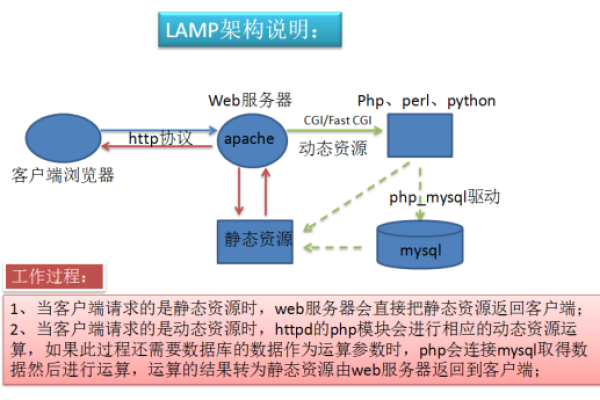

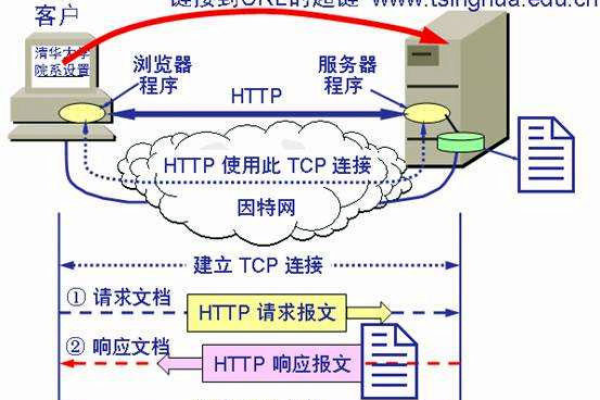


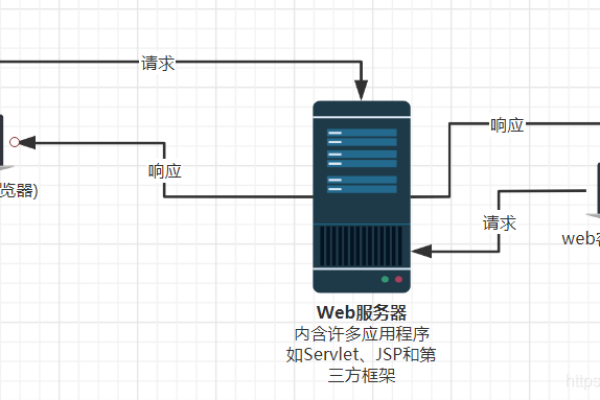

热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

CFTPSSL证书是什么?它如何提升文件传输的安全性?
2024-12-15