
上一篇
What is the MapReduce Library and How Does it Work?
MapReduce是一种编程模型,用于处理和生成大数据集,通过将任务分解为多个小任务并行执行。
MapReduce 编程模型详解

MapReduce 是一个分布式运算程序的编程框架,广泛用于大数据处理和分析,它的核心思想是将复杂的计算过程高度抽象为两个函数:Map 和 Reduce,从而简化了并行计算的实现,以下是对 MapReduce 的详细介绍,包括其定义、优缺点、核心思想、节点主从结构、运行流程及具体案例分析。
MapReduce 的定义及核心思想
MapReduce 由谷歌提出并广泛应用于 Hadoop 生态系统中,用于处理大规模数据集,它允许用户通过编写简单的 Map 和 Reduce 函数来自动分布式处理大量数据,MapReduce 的核心思想是“分而治之”,即将一个大任务分解成多个小任务并行处理,最终将结果汇总。
MapReduce 的优点
1、易编程:用户只需实现 Map 和 Reduce 函数,即可完成复杂的分布式计算任务。
2、良好的扩展性:可以通过增加机器数量来提高计算能力。
3、高容错性:设计之初就考虑到在廉价 PC 集群上运行,能够自动处理节点故障。
4、适合海量数据处理:可以处理 PB 级以上的数据,通过上千台服务器并发工作。
MapReduce 的缺点
1、不擅长实时计算:无法在毫秒或秒级内返回结果,不适合实时应用。
2、不擅长流式计算:输入数据集必须是静态的,不能处理动态变化的数据。
3、不擅长 DAG(有向图)计算:多阶段依赖会导致大量磁盘 I/O 操作,性能低下。
MapReduce 的核心思想
MapReduce 将计算过程分为两个阶段:
1、Map 阶段:每个 MapTask 并行运行,处理输入数据的一小部分,将结果以键值对的形式输出。
2、Reduce 阶段:每个 ReduceTask 并行运行,处理所有 MapTask 输出的相同键的值集合,生成最终结果。
MapReduce 的节点主从结构
MapReduce 采用 Master/Slave 架构:
JobTracker:负责作业调度和资源管理。
TaskTracker:执行具体的 MapTask 和 ReduceTask。
MapTask:执行 Map 函数,将输入数据转换为键值对。
ReduceTask:执行 Reduce 函数,处理相同键的值集合。
MapReduce 的运行流程
1、提交作业:客户端提交作业到 JobTracker。
2、分配任务:JobTracker 根据输入数据划分,分配 MapTask 和 ReduceTask。
3、Map 阶段:读取数据,调用 Map 函数处理,输出键值对。
4、Shuffle 阶段:将 Map 输出按照键分区、排序并传递给 ReduceTask。
5、Reduce 阶段:合并相同键的值,生成最终结果并输出。
MapReduce 案例分析
以网站日志大数据分析为例,使用 MapReduce 进行日志预处理、统计分析和可视化展示:
1、研究背景:随着互联网技术的发展,网站流量增大,日志分析变得重要。
2、研究目的:利用 MapReduce 对网站日志进行大数据分析,获取关键指标。
3、研究意义:帮助网站管理者了解用户行为,优化运营策略。
4、实施步骤:上传日志数据到 HDFS;使用 MapReduce 进行数据预处理;用 Hive 进行统计分析;通过 Sqoop 导出结果到 MySQL;用 ECharts 进行数据可视化。
5、搭建环境:部署 Hadoop 系统,安装必要的组件。
6、具体操作:编写 MapReduce 程序进行日志清洗;使用 Hive 进行复杂查询;导出分析结果并进行可视化展示。
FAQs
问题1:MapReduce 如何处理节点故障?
答案1:MapReduce 设计具有高容错性,当某个 TaskTracker 节点故障时,JobTracker 会自动将该节点的任务重新分配给其他节点执行,确保任务完成,整个过程无需人工干预。
问题2:为什么 MapReduce 不适合实时计算?
答案2:MapReduce 的设计目标是处理离线海量数据,其任务执行时间较长,无法在毫秒或秒级内返回结果,因此不适合实时计算场景。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/6809.html
相关文章
-

Unveiling the Mystery of UE4CDN: Whats Behind This Enigmatic Abbreviation?,这个疑问句标题旨在吸引那些对UE4CDN这一缩写词或其背后概念感到好奇的读者。通过使用Unveiling the Mystery和Whats Behind This Enigmatic Abbreviation?这样的短语,标题传达了探索和揭示未知信息的意图,激发读者的好奇心,促使他们点击阅读以获取更多信息。
-
How does the English translation of Information Security Level Protection relate to activating circuit breaker protection functions for source site security?
-
How does the English translation of Information Security Level Protection relate to enabling circuit breaker protection for source site security?
-
How does activating the circuit breaker protection feature enhance the security of the source station?
-

processes_镜像保存时报错“there are processes in 'D' status, please check process status using 'ps aux' and kill all the 'D' status processes”或“Buildimge,False,Error response from daemon,Cannot pause container xxx”如何解决?
-
Nginx Worker Processes: What Are They and How Do They Work?
-
MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-

What is an Airplane Proxy Server and What Does It Mean in English?
-

What Are the Key Considerations for Choosing a Dedecms English Template for Your English Website Program?
-
What Does the Abbreviation for Domain Name Servers Stand For?
-
How to Activate the Circuit Breaker Protection Feature for Source Station Security in Information Security Level Protection?
-

What are the key points to consider when drafting an opensource software statement in English?
-

What is the significance of registering a companys domain name in abbreviated form?
-
published_"The API does not exist or has not been published in the environment."如何解决?
-
Which are the top 8 free and open JavaScript libraries for drawing?
-

What is the English term for a network administrators server?
-
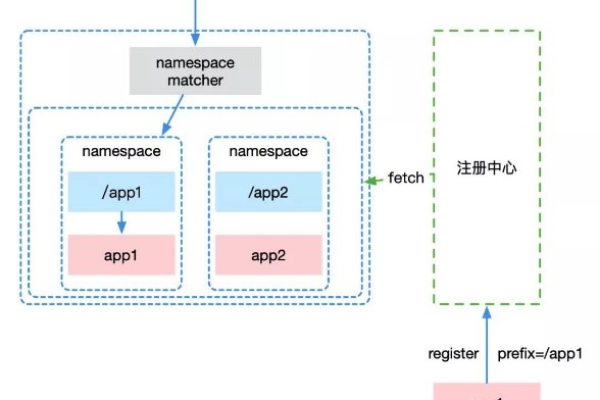
JavaScript在MapReduce框架中为何不兼容,导致mapreduce.js的javascript_MapReduce不支持?
-

How can incorporating motivational quotes in English enhance the design and appeal of a webpage?
-
What Does Domain Registration in English Mean?
-
What are the top 14 WordPress themes ideal for startups?