CDN劫持与杀毒安全性问题解析标题,CDN劫持如何影响杀毒软件的防护能力?

CDN 劫持是一种网络攻击,可通过安装正规杀毒软件、及时更新系统与软件、谨慎访问网站等措施来防范。
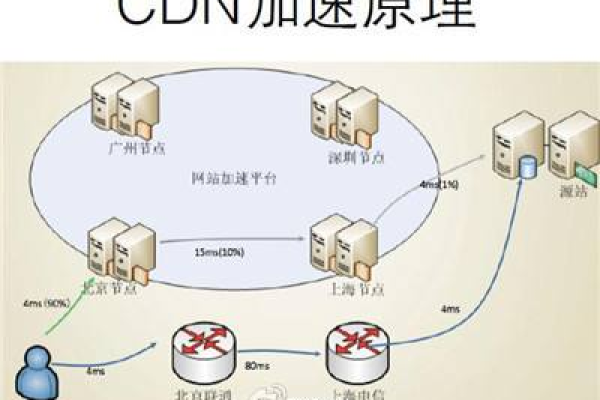
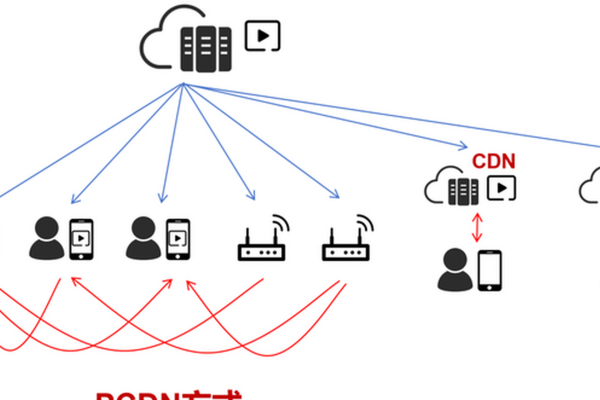
一、CDN劫持
1、定义:CDN劫持是指破解通过各种手段,将用户对正常网站的访问请求重定向到反面网站或改动网站内容,以达到窃取用户信息、传播反面软件等目的,这种劫持通常是针对CDN(内容分发网络)的域名解析或缓存服务器进行的。
2、危害:CDN劫持会导致用户访问的网站内容被改动,可能泄露用户的个人信息和敏感数据,反面网站可能会利用用户的设备进行挖矿、传播干扰等反面行为,给用户带来严重的安全风险,CDN劫持还会影响网站的声誉和信誉,导致用户流失。
3、原理:破解通常通过改动DNS服务器的记录,将用户对正常网站的访问请求解析到反面网站,或者利用CDN缓存服务器的破绽,将反面内容注入到缓存中,使用户在访问时获取到被改动的内容。

二、防范措施
| 小标题 | |
| 启用HTTPS | HTTPS通过SSL/TLS协议对数据进行加密,确保数据在传输过程中不会被劫持和改动,选择合适的SSL/TLS证书并正确安装,强制HTTP请求重定向到HTTPS。 |
| 使用CDN供应商的安全功能 | 许多CDN供应商提供丰富的安全功能,如Web应用防火墙(WAF)、DDoS防护等,启用这些功能可以有效地增强网站的安全性。 |
| 监控流量和日志 | 实时监控流量和日志可以帮助及时发现并响应CDN被劫持的情况,通过分析流量模式和服务器日志,可以发现异常流量和潜在的攻击迹象。 |
| 选择可信的CDN供应商 | 选择一家可信的CDN供应商是防止CDN被劫持的重要一步,可信的供应商通常具备完善的安全措施和良好的服务保障。 |
| 定期安全审计和渗透测试 | 定期进行安全审计和渗透测试,可以发现并修复潜在的安全破绽,从而降低CDN被劫持的风险。 |
| 加强员工安全意识 | 员工的安全意识对于防止CDN被劫持也是至关重要的,定期进行安全培训和演练,可以提高员工的安全意识和应对技能。 |
三、相关问题解答
1、什么是CDN?
CDN即内容分发网络,是一种利用分布式节点技术,将网站内容分发到全球各地的服务器,以提高用户访问速度和稳定性的技术。

2、如何判断CDN是否被劫持?
可以通过检查网站的URL是否正确,是否被重定向到其他网站;检查网站的内容是否正常,是否显示出现异常的广告或反面内容;使用不同的网络环境和设备进行访问,看是否出现一致的问题来判断CDN是否被劫持。

面对日益复杂的网络安全环境,采取多层次、全方位的安全防护策略显得尤为重要,通过综合运用上述防范措施,可以有效提升CDN服务的安全性,保护用户数据免受劫持威胁,持续关注安全动态,及时调整防御策略,也是确保网络安全不可或缺的一环。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20