脚本错误CDN如何解决?

脚本错误与 CDN 的深度剖析
一、脚本错误
在当今数字化的网络环境中,脚本错误是一种较为常见的技术问题,脚本是一系列由计算机执行的命令或指令集合,常用于网页开发、软件应用以及自动化任务等众多领域,当脚本在运行过程中出现不符合预期的情况,例如语法错误、逻辑错误、运行时错误等,就会导致脚本错误,这种错误可能会使网页部分功能无法正常使用,软件出现异常行为,甚至导致整个程序崩溃,严重影响用户体验和业务流程的正常进行。
二、CDN 基础知识
(一)定义与原理
分发网络(CDN)是一种分布式服务器系统,其核心原理是将网站的静态资源(如图片、视频、样式表、脚本文件等)缓存到全球多个节点服务器上,当用户请求访问网站时,CDN 会根据用户的地理位置、网络状况等因素,智能地将用户请求定向到距离最近且负载较轻的节点服务器,使用户能够快速获取所需资源,从而提高网站的访问速度和性能,减少服务器负载和网络拥塞。

(二)主要功能
| 功能 | 描述 |
| 加速内容交付 | 通过在全球分布节点缓存资源,缩短数据传输距离,加快用户访问速度。 |
| 负载均衡 | 分散用户请求到多个服务器,避免单个服务器过载,提高系统稳定性。 |
| 提高可用性 | 即使某个节点出现故障,其他节点仍可提供服务,保障网站持续运行。 |
三、脚本错误与 CDN 的关联
(一)缓存机制引发的问题
CDN 的缓存机制可能导致脚本版本更新不及时,当网站开发者对脚本进行修改并部署后,CDN 缓存未及时刷新,用户可能仍然获取到旧版本的脚本,从而引发脚本错误,新脚本中修复了某个函数的逻辑错误,但由于缓存原因,用户端执行的仍是旧脚本,就会出现该函数运行异常的情况。
(二)配置不当的影响
错误的 CDN 配置也可能与脚本错误相关,CDN 对某些脚本文件的缓存策略设置不合理,如缓存时间过长或过短,都可能影响脚本的正常运行,过长的缓存时间会使脚本更新延迟,而过短的缓存时间可能导致频繁回源获取脚本,增加服务器压力并可能因网络波动等原因导致脚本获取不完整或出错。
四、解决脚本错误与 CDN 相关问题的策略

(一)及时更新缓存
网站管理员应在脚本更新后,及时通过 CDN 提供商的管理界面或使用相关 API 来刷新 CDN 缓存,确保用户能够尽快获取到最新版本的脚本文件,可以设置合理的缓存过期时间,根据脚本的更新频率和重要性进行调整,以平衡性能与及时性。
(二)优化 CDN 配置
仔细审查和优化 CDN 的配置参数,针对不同类型的脚本文件制定合适的缓存策略,对于经常更新的脚本,可以适当缩短缓存时间;对于相对稳定的脚本,可以延长缓存时间,还可以启用 CDN 的实时监控功能,及时发现并处理可能出现的缓存异常情况。
五、相关问题与解答
(一)问题:如何判断脚本错误是由 CDN 引起的?

解答:可以通过以下几种方法来判断,检查浏览器控制台报错信息,若提示脚本文件的版本与预期不符,可能是 CDN 缓存未更新,对比本地开发环境和线上环境,如果在本地正常而线上出现脚本错误,且排除了代码本身问题后,很可能是 CDN 相关因素导致,查看 CDN 提供商的日志和监控数据,若有关于脚本文件缓存或分发的异常记录,也能辅助判断。
(二)问题:刷新 CDN 缓存后,为什么有时还会看到脚本错误?
解答:这可能是由于多种原因导致的,可能存在缓存刷新不完全的情况,部分节点服务器上的缓存未能成功更新,如果在刷新缓存过程中又有新的请求到达,可能会获取到新旧版本混合的缓存内容,网络延迟或不稳定也可能导致刷新后的缓存未能及时同步到所有节点,从而使部分用户仍然遇到脚本错误,可以尝试再次刷新缓存,并检查 CDN 的全局配置和各个节点的状态,确保缓存更新的完整性和一致性。
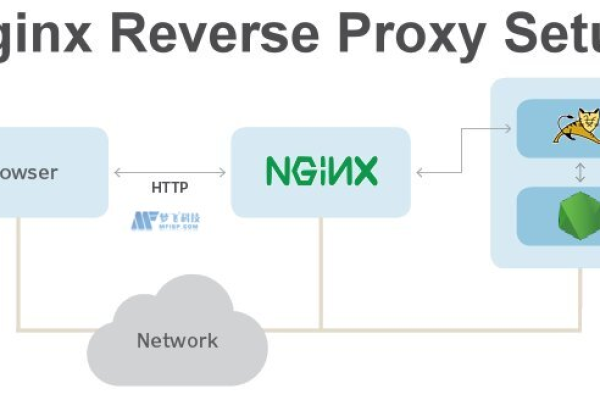

热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22