关于安全用电打折的疑问标题,安全用电优惠活动,如何确保安全折扣两不误?

保障电力使用安全与经济效益的双赢策略
在现代社会,电力已经成为人们生活和工作中不可或缺的能源,随着电力需求的不断增长,电力安全问题也日益凸显,为了确保电力使用的安全,同时实现经济效益,安全用电打折成为了一种有效的策略,本文将详细探讨安全用电打折的概念、实施方法以及其带来的好处。
一、安全用电打折的概念
安全用电打折是指在电力供应和使用过程中,通过采取一系列安全措施和管理手段,降低电力事故的发生率,提高电力使用效率,从而实现电力成本的降低和经济效益的提升,这种策略不仅有助于保障电力系统的安全稳定运行,还能为用户节省电费支出,实现双赢。
二、安全用电打折的实施方法
(一)加强电力设施建设和维护
1、电网升级改造
对老旧电网进行升级改造,提高电网的供电能力和可靠性,更换老化的输电线路、变压器等设备,减少因设备故障导致的停电事故。
建设智能电网,实现对电力系统的实时监测和控制,通过智能电表、传感器等设备,及时获取电网运行数据,预测和防范电力故障。
2、定期维护和检修
制定详细的电力设施维护计划,定期对电力设备进行检查、维修和保养,每年对变压器进行一次全面检查,每季度对输电线路进行巡检,及时发现和处理潜在的安全隐患。
建立应急抢修机制,一旦发生电力故障,能够迅速组织人员进行抢修,缩短停电时间。

(二)推广节能电器和技术
1、节能电器普及
鼓励用户购买和使用节能电器,如节能灯、节能冰箱、节能空调等,这些电器在满足用户使用需求的同时,能够有效降低电能消耗。
开展节能电器促销活动,通过打折、补贴等方式,降低节能电器的购买成本,提高用户的购买积极性。
2、节能技术应用
在工业生产中,推广应用先进的节能技术,如变频调速技术、余热回收利用技术等,这些技术能够提高生产设备的能源利用效率,减少能源浪费。
在建筑设计中,采用节能设计理念,如合理的建筑朝向、保温隔热材料的应用等,降低建筑物的能耗。
(三)加强电力安全管理
1、安全教育和培训

开展电力安全知识宣传教育活动,提高用户的安全意识和自我保护能力,通过社区宣传、学校教育、媒体报道等方式,向公众普及电力安全知识。
对企业员工进行电力安全培训,使其熟悉电力设备的操作规程和安全注意事项,减少因人为操作失误导致的电力事故。
2、安全监管和执法
加强对电力市场的监管,规范电力企业的经营行为,对电力企业的资质进行审核,确保其具备相应的技术和管理能力。
加大对电力违法行为的打击力度,依法查处窃电、违规用电等行为,维护电力市场秩序。
三、安全用电打折带来的好处
(一)保障电力安全
通过加强电力设施建设和维护、推广节能电器和技术、加强电力安全管理等措施,能够有效降低电力事故的发生率,保障电力系统的安全稳定运行,这不仅可以减少因停电给用户带来的不便和损失,还能避免因电力事故引发的火灾、爆炸等严重后果。

(二)提高经济效益
安全用电打折策略的实施,可以降低电力成本,提高电力使用效率,对于用户来说,购买节能电器、采用节能技术可以降低电费支出;对于企业来说,提高生产效率、降低能耗可以提高经济效益,减少电力事故的发生也可以降低电力企业的维修成本和社会的经济损失。
(三)促进可持续发展
节能电器和技术的推广应用,有助于减少能源消耗和温室气体排放,促进可持续发展,在全球气候变化日益严峻的背景下,节约能源、保护环境已经成为各国的共同目标,安全用电打折策略的实施,符合可持续发展的要求,有利于推动经济社会的绿色发展。
四、相关问答FAQs
问题1:安全用电打折策略是否会影响电力供应的稳定性?
答:不会,安全用电打折策略旨在通过加强电力设施建设和维护、推广节能电器和技术、加强电力安全管理等措施,提高电力系统的可靠性和稳定性,这些措施不仅不会影响电力供应的稳定性,反而能够增强电力系统的抗灾能力和应急响应能力,确保在各种情况下都能为用户提供稳定的电力供应。
问题2:如何确保安全用电打折策略的有效实施?
答:为确保安全用电打折策略的有效实施,需要政府、企业和社会各界的共同努力,政府应加强政策引导和监管,制定相关的法律法规和标准规范;企业应积极履行社会责任,加大技术研发和创新投入,提高电力设施的安全性和可靠性;社会各界应积极参与电力安全宣传教育活动,提高公众的安全意识和自我保护能力,只有各方齐心协力,才能确保安全用电打折策略的有效实施,实现保障电力安全和提高经济效益的双赢目标。
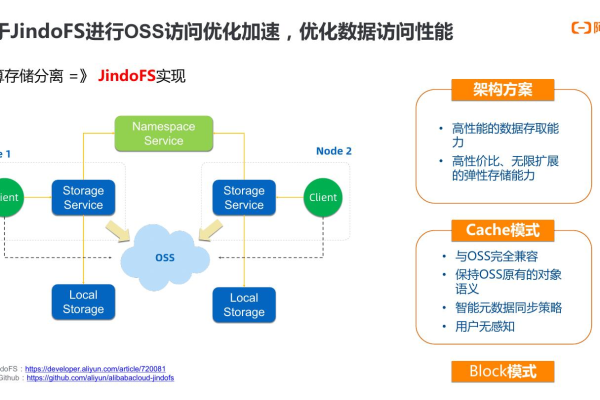



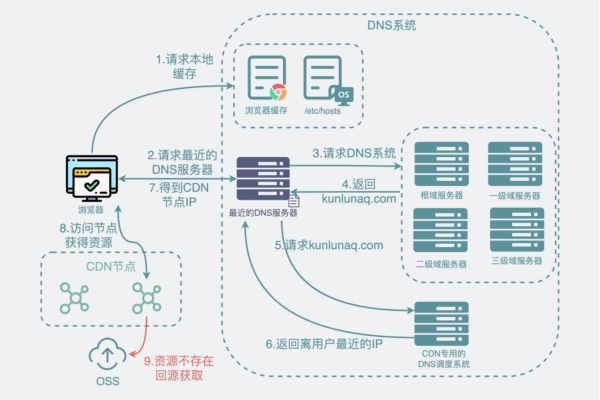

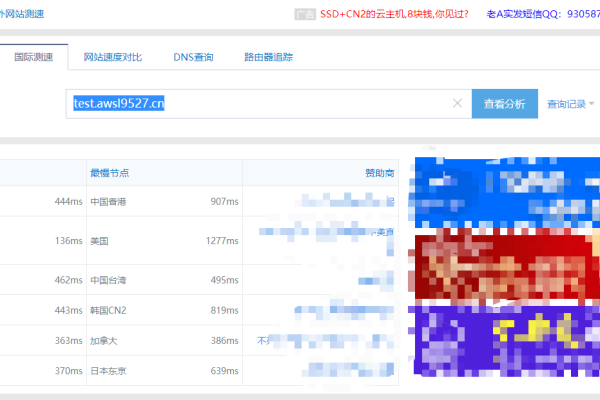


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20