CDN技术究竟在哪些领域得到了广泛应用?

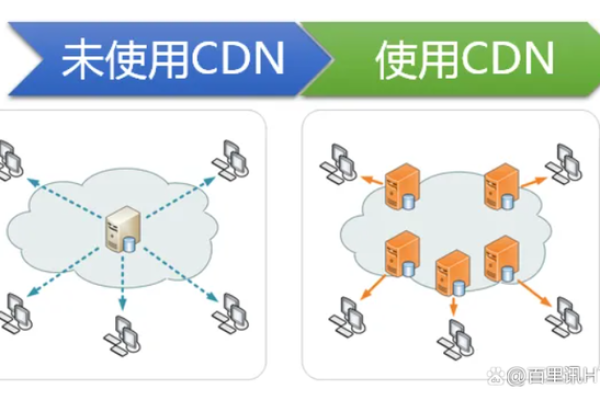
CDN,即内容分发网络(Content Delivery Network),是一种通过在多个地理位置分布的服务器节点上缓存和分发内容的技术,其核心目的是提高用户访问速度、提升网站性能、降低延迟,并减轻源站服务器的压力,CDN广泛应用于各种场景,以下是对其应用范围的详细介绍:
如图片、CSS、JavaScript文件等,是网站加载过程中最耗时的部分之一,CDN通过将这些静态资源缓存到全球各地的边缘节点上,使用户能够从最近的节点获取这些资源,从而显著减少加载时间,这种加速方式适用于所有需要快速加载的网站类型,如电商网站、新闻门户、社交媒体平台等。
二、视频流媒体加速
随着视频内容的普及,视频流媒体服务对带宽和传输速度的要求越来越高,CDN为视频平台提供稳定、快速的内容分发服务,确保视频流畅播放,减少缓冲时间和播放中断,无论是在线直播还是点播视频,CDN都能通过优化传输路径和缓存机制来提升用户体验。
三、在线游戏加速
在线游戏对低延迟和高稳定性有着极高的要求,CDN通过智能路由和负载均衡技术,将游戏数据传输到离玩家最近的边缘节点,从而降低延迟,提高游戏的流畅性和稳定性,这对于多人在线竞技游戏尤为重要,因为任何微小的延迟都可能影响游戏体验。

四、电子商务加速
电子商务网站对页面加载速度有着严格的要求,因为加载速度直接影响到用户的购物体验和转化率,CDN通过加速商品图片、网页内容等的传输,提高网站的加载速度,从而提升用户购物体验,CDN还可以帮助电子商务网站应对突发流量高峰,确保网站在促销活动期间依然保持稳定运行。
五、移动应用加速
移动应用中的图片、视频、API响应等可以通过CDN加速,提高应用的启动速度和响应速度,特别是在网络状况不佳的地区,CDN的作用更加显著,通过使用CDN,移动应用可以更快地加载内容,减少用户等待时间,提升用户体验。
六、安全防护
CDN不仅提供加速服务,还具备强大的安全防护能力,它可以分散DDoS攻击流量,减轻分布式拒绝服务攻击的影响;同时支持HTTPS协议,为用户提供安全的数据传输服务,对于需要保护敏感数据或防止反面攻击的网站和应用来说,CDN是一个不可或缺的安全屏障。
七、全球化服务
对于跨国企业、国际电商平台以及全球化的应用来说,CDN的全球部署可以帮助它们更好地服务全球用户,通过将内容缓存到全球各地的节点上,CDN能够确保不同地区的用户都能获得快速的访问体验,这种全球化的服务能力使得CDN成为国际化业务不可或缺的一部分。

八、大规模活动支持
在大型促销活动、节日庆典、线上发布会等场景下,网站或应用往往会面临突发流量高峰,CDN通过分发大量静态内容和动态内容,确保高并发访问时的稳定性和性能,这种应对突发流量的能力使得CDN成为大规模活动的重要技术支持。
九、企业内网加速
企业内部的文件共享、应用访问等也可以通过CDN加速,提高员工的工作效率,特别是对于远程办公场景来说,CDN可以减少内部网络延迟,提高数据传输速度,这种内部加速能力使得CDN在企业内部网络优化中发挥着重要作用。
十、API加速
API服务提供商、开发者平台等可以通过CDN缓存和智能路由API请求,减少响应时间,提高API的可用性和性能,这对于需要频繁调用API的服务来说尤为重要,因为任何API响应时间的延长都可能影响到整个应用的性能和用户体验。

CDN作为一种高效的内容分发技术,在多种场景下都能发挥重要作用,它通过将内容分发到全球各地的节点服务器上,显著提高了内容的传输速度和稳定性,降低了延迟和运营成本,在未来的发展中,随着互联网技术的不断进步和应用场景的不断拓展,CDN技术将在更多领域发挥重要作用。







热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20