
上一篇
如何在多轮MapReduce任务中优化配置以利用多CPU内核的计算能力?
在多轮MapReduce任务中,优化配置至关重要。增加CPU内核可以加速处理,但需平衡负载。调整内存分配和I/O缓冲区大小也很关键。合理设置可以减少任务执行时间,提高效率。
在当今的大数据时代,MapReduce已成为处理大规模数据集的一种重要编程模型,随着计算需求的增加和硬件技术的发展,拥有多CPU内核的服务器越来越普遍,本文将深入探讨在多CPU内核环境下,如何对MapReduce进行有效的调优配置,以提升其性能和效率。

服务器端配置
Yarn服务参数配置
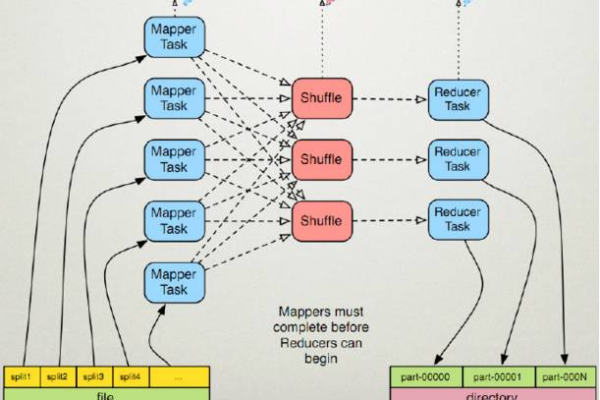
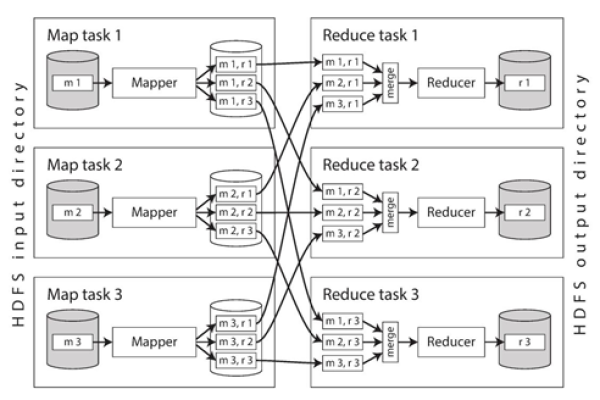
在多CPU内核环境中,适当调整Yarn的服务参数是关键步骤之一,通过进入Yarn服务的“全部配置”界面,并根据CPU核心数进行相应的参数设置,可以有效提高MapReduce作业的并发处理能力,当CPU内核数为磁盘数的3倍时,应优先调整内存和CPU相关的资源配置,如内存分配和虚拟CPU的核心数。
内存配置:每个Map或Reduce任务分配的内存应适度,过大或过小都会影响到系统的整体效率,一个常见的做法是根据实际的CPU核心数和总内存来平衡每个任务使用的内存量。
CPU资源配置:合理配置每个任务使用的虚拟核心数量,可以有效利用多核CPU的计算能力,避免单个核心过载而其他核心空闲的情况。
客户端配置
MapReduce客户端的配置同样重要,它直接影响到作业提交和执行的效率,配置文件通常位于客户端安装目录下的/HDFS/hadoop/etc/hadoop/mapredsite.xml路径中。
任务并发数配置:在多CPU环境下,增加每节点的任务(map、reduce)并发数是一个有效的优化手段,这可以通过调整mapredsite.xml中的相关配置实现,例如mapreduce.job.running.map.limit和mapreduce.job.running.reduce.limit。
资源分配策略:根据不同作业的需求,选择合适的资源分配策略,如公平调度器或容量调度器,可以在多用户共享环境下平衡资源使用,优化整体系统性能。
操作系统级别调优
内核参数调整
操作系统级别的调优对于充分利用多CPU内核环境非常重要,修改操作系统的内核参数可以大幅提升Hadoop集群的性能。
增大文件描述符上限:调整net.core.somaxconn和epoll的文件描述符上限,可以支持更多的并发网络连接,提高数据处理速度。
关闭swap:虽然swap可以为系统提供更多的虚拟内存,但在MapReduce作业中,频繁的swap操作会大大降低性能,在配置有足够物理内存的情况下,关闭swap是一个更有效的选择。
预读缓存区大小调整
通过增加预读缓存区的大小,可以减少磁盘寻道次数和I/O等待时间,从而提高数据处理速度,这在处理大量顺序数据时尤为有效。
Hdfs参数调优
coredefault.xml配置
在Hdfs的配置文件coredefault.xml中,调整hadoop.tmp.dir可以优化数据的临时存储位置,确保该目录位于高性能的磁盘上,可以加快数据读写速度。
相关问答FAQs
如何在多CPU环境下优化MapReduce性能?
在多CPU环境下,可以通过以下几种方式优化MapReduce的性能:
调整每个Map和Reduce任务的内存和CPU资源分配,确保资源充分利用。
增加任务的并发数,特别是在CPU资源充足的情况下。
优化操作系统的网络和I/O设置,例如增大文件描述符上限和调整预读缓存区大小。
为什么在多CPU内核环境下关闭swap是一个好选择?
在多CPU内核环境下,系统通常配备有更多的物理内存,Swap操作虽然能提供额外的虚拟内存,但其读写速度远低于物理内存,并且在内存与磁盘之间频繁交换数据会严重影响性能,在物理内存充足的情况下关闭swap,可以避免这种性能损耗,从而提高整体的处理速度。
通过上述各方面的配置和调优,可以显著提升多CPU内核环境下MapReduce的性能,这些优化措施不仅涵盖了软件层面的配置,也包括了操作系统级别的调优,从多个层面确保了数据处理的高效和稳定,希望这些信息对正在寻求改善其MapReduce作业性能的用户有所帮助。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/66070.html
相关文章
如何在多轮MapReduce任务中优化多CPU内核的配置以提高效率?
如何在多轮MapReduce任务中优化多CPU内核的配置?
如何优化多轮MapReduce任务在多CPU内核环境下的配置?
在多轮多CPU内核环境中,如何进行MapReduce任务的优化配置以最大化效率?
如何在多轮和多CPU内核环境下实现MapReduce调优的详细配置策略?

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
在多个MapReduce串联和多个NameService环境下,MapReduce任务失败的原因是什么?
如何有效解决MapReduce任务中的pending_MapReduce问题?








