9120cdn,神秘网络世界探索,真相如何?

9120cdn:内容分发网络的深度解析与应用
一、CDN的基本概念
(一)定义
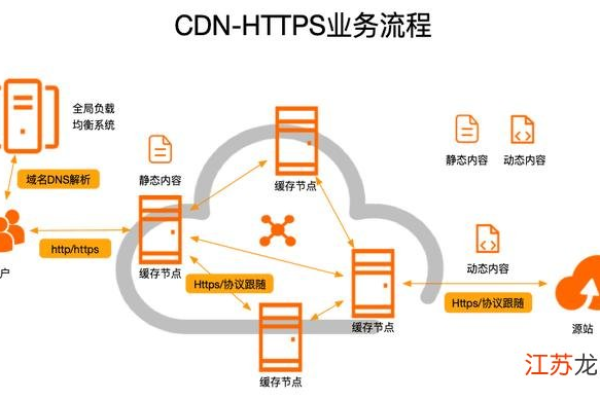
CDN即内容分发网络(Content Delivery Network),它通过在多个地理位置部署服务器节点,将网站的内容缓存到离用户最近的节点上,使用户能够更快地获取所需的数据和资源。
(二)工作原理
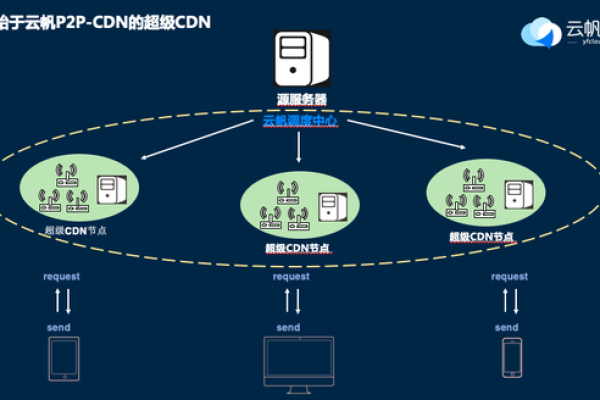
当用户请求某个网站的内容时,CDN会根据用户的地理位置、网络状况等因素,智能地选择距离用户最近且负载较轻的节点来提供服务,如果该节点已经缓存了用户请求的内容,就直接从节点返回给用户;如果没有缓存,则从源服务器获取内容,同时将内容缓存到该节点,以备后续用户访问。
二、9120cdn的特点与优势
(一)特点
| 特点 | 描述 |
| 分布式架构 | 在全球多个地区部署节点,形成分布式网络,提高服务的可用性和稳定性。 |
| 智能调度 | 根据用户的位置、网络状况等实时动态地分配最优的节点,确保用户获得最佳的访问体验。 |
| 缓存技术 | 采用高效的缓存算法,对热门内容进行缓存,减少源服务器的负载,加快内容传输速度。 |
(二)优势
提高网站性能:通过缓存和就近服务,大大减少了数据传输的延迟,提高了网站的加载速度,提升了用户体验。
减轻源服务器压力:大部分请求由CDN节点处理,降低了源服务器的负载,使其能够更专注于核心业务的处理。

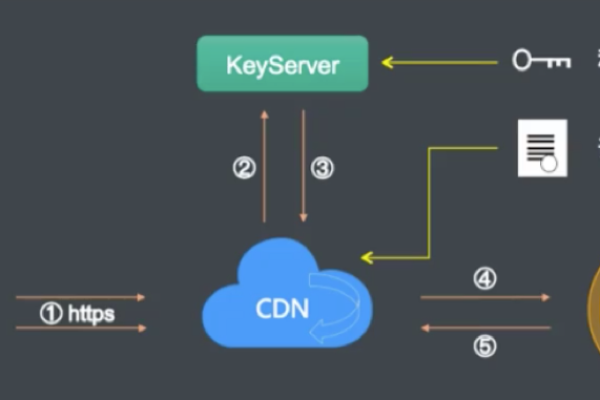
增强安全性:CDN可以隐藏源服务器的真实IP地址,防止破解攻击和反面流量的直接冲击,同时提供一些安全防护功能,如DDoS防护等。
三、9120cdn的应用场景
(一)网站加速
对于各类网站,无论是企业官网、电商平台还是新闻媒体网站,使用9120cdn都可以显著提高网站的访问速度,降低页面加载时间,吸引更多的用户并提高用户的满意度。
(二)视频点播与直播
在视频领域,CDN能够确保视频内容的流畅播放,避免卡顿和缓冲现象,对于视频点播平台和直播服务提供商来说,9120cdn是保证服务质量的关键基础设施。
(三)软件下载
对于软件开发商和发行商,9120cdn可以加快软件下载速度,提供稳定可靠的下载服务,提高软件的推广和传播效率。

四、相关问题与解答
(一)问题:如何判断一个CDN服务的好坏?
解答:可以从以下几个方面来判断:
节点分布:优质的CDN应在全球范围内有广泛而合理的节点分布,能够覆盖主要的用户群体和地区。
缓存命中率:较高的缓存命中率意味着CDN能够有效地利用缓存资源,减少对源服务器的依赖,提高服务效率。

网络性能:包括带宽、延迟、丢包率等指标,可以通过专业的测试工具进行检测和评估。
技术支持与服务质量:良好的技术支持团队能够及时解决用户在使用过程中遇到的问题,提供优质的服务保障。
(二)问题:使用CDN是否会影响网站的安全性?
解答:使用正规的CDN服务一般不会对网站的安全性造成负面影响,反而有助于增强网站的安全性,如前所述,CDN可以隐藏源服务器的真实IP地址,防止破解直接攻击源服务器,许多CDN提供商还提供了一系列的安全防护功能,如DDoS防护、防盗链等,能够有效地抵御各种网络攻击和安全威胁,在选择CDN服务提供商时,需要选择信誉良好、安全可靠的供应商,以确保网站的安全和稳定运行。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22