CDN周边产业,发展现状及未来趋势如何?

一、CDN
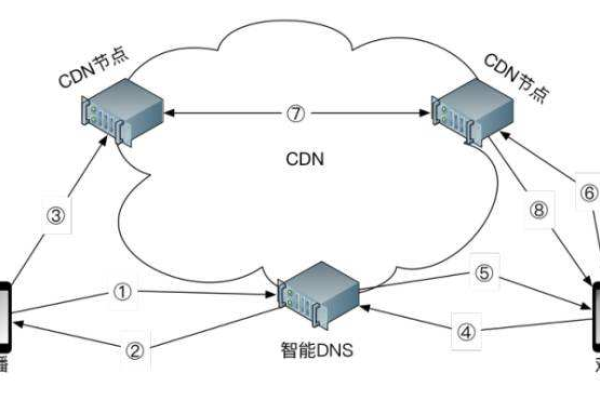
CDN,即内容分发网络,是一种通过在互联网中分布部署服务器节点,将用户请求的数据内容及时地从最近的服务器节点返回给用户的技术,从而解决Internet网络拥挤的状况,提高用户访问的响应速度和成功率,提升业务的使用体验。
二、CDN产业链分析
| 环节 | 描述 | 代表企业 |
| 上游 | 包括硬件设备(如服务器、存储设备等)和电信运营企业(提供数据中心、互联网带宽等关键通信资源) | 新华三、华为、移动、联通、电信等 |
| 中游 | CDN服务提供商,从上游租用或采购资源,为下游内容提供商提供网络加速服务 | 网宿科技、百度云、阿里云、酷盾安全、七牛云等 |
| 下游 | 内容分发网络服务的使用者,如视频、电商、游戏、金融等服务提供商 | 优酷、爱奇艺、百度、京东、天猫等 |
三、CDN周边产业
1、云计算与边缘计算:随着云计算与边缘计算等前沿技术的兴起,CDN行业正经历前所未有的技术创新浪潮,这些技术的深度融合不仅极大地增强了CDN服务的性能与效率,还显著提升了其安全性。
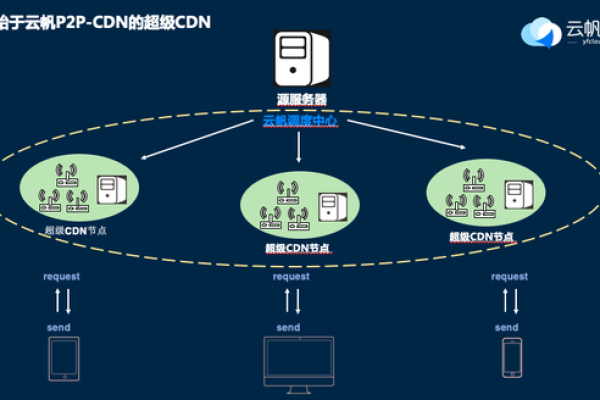
2、共享计算+CDN模式:这是一种创新的CDN建设方式,通过已授权的智能硬件设备收集家庭用户中闲置的带宽资源,并转化为CDN服务,这种模式具有灵活、成本低、覆盖广等优势,能够应对瞬时高并发等情况。

3、安全服务:随着网络安全问题的日益突出,CDN安全服务成为周边产业的重要组成部分,这包括DDoS攻击防护、WAF(Web应用防火墙)等安全服务,以确保CDN服务的稳定运行和数据安全。
4、数据分析与优化:通过对CDN服务数据的收集和分析,可以优化CDN网络的性能和服务质量,这包括流量分析、负载均衡、缓存策略等方面的优化。
5、定制化服务:针对不同行业的需求,CDN服务提供商可以提供定制化的解决方案和服务,针对在线教育、远程办公等行业的特殊需求,提供定制化的加速和安全解决方案。

四、相关问题与解答
1、问题:CDN服务的主要优势是什么?
回答:CDN服务的主要优势在于提高用户访问的响应速度和成功率,提升业务的使用体验,通过在互联网中分布部署服务器节点,CDN能够将用户请求的数据内容及时地从最近的服务器节点返回给用户,从而解决Internet网络拥挤的状况。
2、问题:CDN行业的未来发展趋势是什么?

回答:CDN行业的未来发展趋势包括技术创新、市场需求增长和服务多元化,随着云计算、边缘计算等技术的不断发展,CDN服务将更加智能化、高效化和安全化,随着数字化进程的加速和在线需求的爆发,CDN服务的市场需求将持续增加,CDN服务提供商还将拓展更多的应用场景和服务领域,以满足不同行业的需求。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22