上一篇
如何配置HBase以实现MapReduce的双读功能?
要配置HBase的双读功能,你需要在HBase的配置文件hbasesite.xml中添加以下属性:,,“ xml,,hbase.coprocessor.region.classes,org.apache.hadoop.hbase.coprocessor.DoubleReadCoprocessor,,,hbase.coprocessor.master.classes,org.apache.hadoop.hbase.coprocessor.DoubleReadCoprocessor,,“,,这将启用 双读功能,允许MapReduce作业在读取数据时同时访问HBase的两个不同版本。
在当今大数据时代,HBase作为一款高性能、可伸缩的分布式存储系统,在处理大量结构化数据方面显示出了巨大的优势,为了提高系统的可用性和容错能力,双读功能成为了一个关键的技术点,本文将深入探讨如何配置HBase双读功能,以及这种配置对于提升数据处理效率和稳定性的重要性。

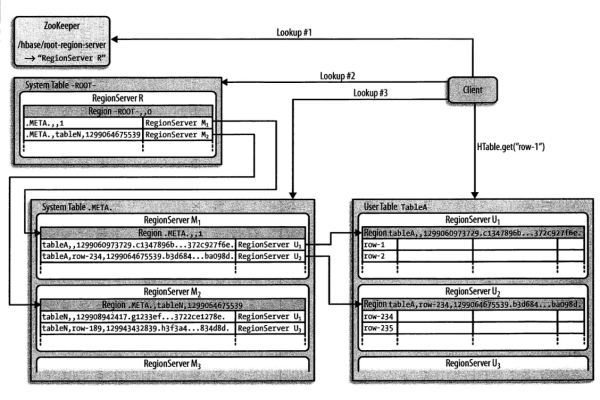
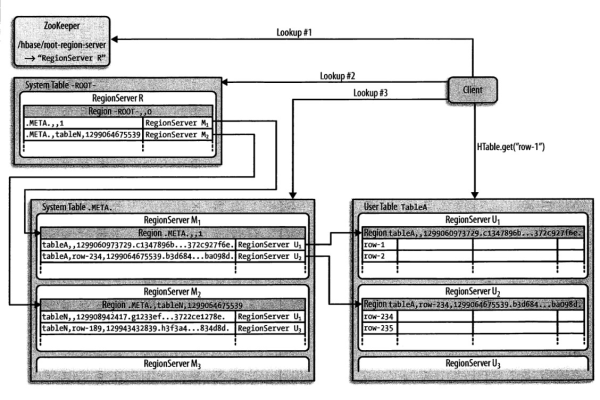
HBase双读功能是指客户端可以同时从主备两个集群读取数据,这不仅提高了读取操作的高可用性,还能在主集群出现问题时,保证数据的持续可访问性,这一特性尤其适用于四个主要场景:使用Get读取数据、使用批量Get读取数据、使用Scan读取数据,以及基于二级索引进行查询。
配置HBase双读功能,需要遵循一系列步骤并注意相关配置项的设置,开发者需要在HBase客户端应用中通过自定义加载主备集群的配置项来实现双读能力,这涉及到对客户端的连接设置进行适当的调整,确保它能同时识别和连接到主备两个集群。
重点介绍具体的配置方法:
1、配置文件的设置
配置文件名:通常涉及一个特定的配置文件,如"hbasedual.xml",在该文件中定义了双读功能所需的所有相关配置项。
配置项详解:hbase.dualclient.active.cluster.config配置项可能用于指定当前活跃的集群配置信息,这些配置项的具体设定决定了双读功能的运行方式和效率。
2、客户端策略
读取策略:客户端需要实现一定的策略来决定何时从主集群读取,何时从备集群读取,以及如何处理从两者获得的数据不一致的情况。
异常处理:在读取过程中可能会遇到各种异常情况,如网络延迟、集群宕机等,客户端应具备相应的处理机制来应对这些问题。
3、代码级别的实现
API调用:在编写客户端代码时,需要利用HBase提供的API进行正确的调用,以支持双读特性。
错误处理:代码中要包含完善的错误处理逻辑,确保在读写过程中遇到的问题能够被有效管理。
4、测试与优化
环境测试:在实施双读功能后,应在测试环境中对其进行充分的测试,以确保功能的正确性和效率。
性能优化:根据测试结果调整配置参数,优化系统性能。
在配置和使用HBase的双读功能时,还有以下注意事项或建议:
定期检查和维护配置文件,确保配置项的准确性。
监控系统的性能表现,特别是在引入新功能后,及时调整策略以应对可能出现的性能下降。
加强对开发和运维团队的培训,确保他们理解双读功能的工作原理和关键配置。
在确保数据高可用性和系统稳定性方面,HBase的双读功能提供了一种有效的解决方案,通过合理的配置和管理,可以显著提高数据处理的效率和可靠性,理解和掌握这一功能的配置方法及应用场景,对于每一个使用HBase的企业和开发者来说都是至关重要的。
FAQs
Q1: HBase双读功能对系统资源有何影响?
Q2: 如果主集群故障,如何处理才能保证数据不丢失?
请根据上文内容,回答上述问题:
Q1: 双读功能由于同时与主备两个集群进行通信,可能会对系统资源造成额外的负担,特别是在网络带宽和客户端处理能力方面,在部署双读功能时,需要评估现有资源是否足够支持增加的负载,必要时应进行适当的资源扩展。
Q2: 若主集群发生故障,系统应能自动切换到备集群继续提供服务,这要求客户端具备故障检测和自动切换的能力,应确保主备集群之间有有效的数据复制机制,以保证任何时候数据的完整性和一致性。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/65898.html
相关文章
-
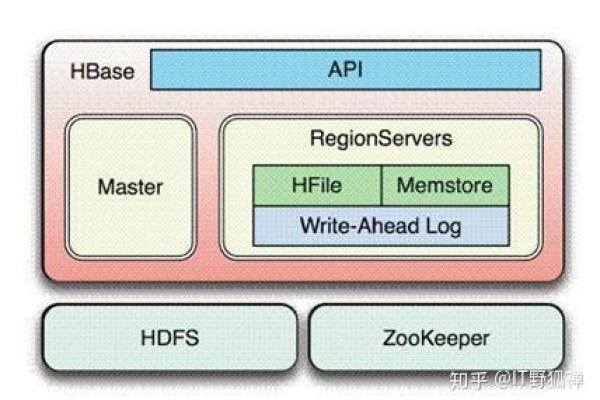
如何配置MapReduce以实现HBase的双读功能?
-
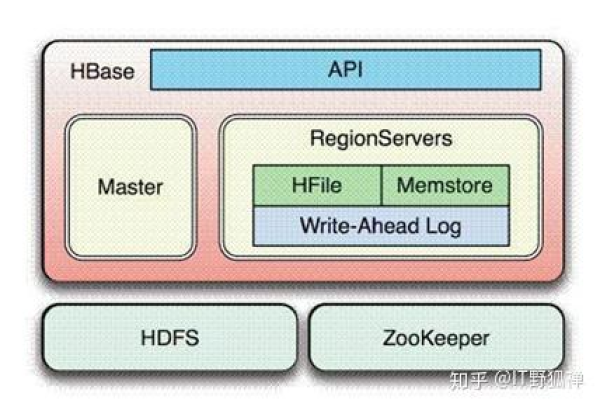
如何配置HBase以实现MapReduce双读功能?
-

MapReduce思想与基本原理解析,如何高效处理大规模数据?,MapReduce是如何革新大规模数据处理的?,解释,这个标题直接指向了MapReduce的核心价值——革新性地处理大规模数据集。它暗示了文章将会探讨MapReduce技术背后的原理,以及它是如何改变我们对数据的处理方式,特别是在面对海量信息时。标题中的如何预示着文章将提供具体的机制和方法,而革新一词则强调了这种技术的突破性和对传统数据处理方法的改进。
-
如何实现HBase在MapReduce任务中的双读配置与优化策略?
-
如何在HBase中配置实现MapReduce的双向读取功能?
-
如何高效完成mapreduce环境的配置与优化?
-
反向索引在MapReduce应用中如何与反向建模技术结合实现高效信息检索?
-
如何有效调优MapReduce Shuffle过程以提升数据处理效率?