CDN在元宇宙中扮演什么角色?

CDN技术作为元宇宙的关键技术支撑,通过其内容分发网络加速服务,显著提升了用户的访问速度和体验,为构建流畅、稳定的 元宇宙环境提供了强有力的保障。
元宇宙,一个融合了虚拟与现实的数字世界,正逐步成为科技发展的新前沿,它不仅改变了人们的娱乐方式,还在教育、工作、社交等多个领域展现出巨大的潜力,要实现一个流畅、稳定且高度沉浸式的元宇宙体验,内容分发网络(CDN)技术的支持至关重要。
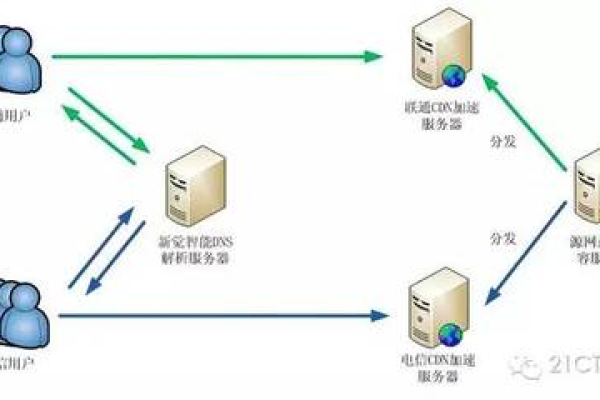
CDN是一种通过全球分布的节点服务器群来优化内容传输的技术,它将数据缓存到离用户更近的节点上,从而减少延迟,提高访问速度和可靠性,在元宇宙中,这种技术显得尤为重要,因为它能够确保用户在任何地点都能获得高质量的互动体验。

边缘计算是CDN技术的核心组成部分之一,它将数据处理能力下放到网络的边缘,即靠近数据源的位置,这样做的好处是可以更快地响应用户需求,减少数据传输的延迟,在元宇宙中,实时交互是非常重要的,边缘计算可以有效提升用户体验,使得虚拟环境更加逼真和流畅。
AgileCDN是一个典型的案例,展示了CDN如何在元宇宙中发挥关键作用,该公司利用其全球260+超级节点,为中小企业提供高效的内容加速服务,这些节点具备强大的边缘计算能力,可以帮助企业降低成本,同时提供安全、稳定的服务,AgileCDN还与多家数据安全公司合作,确保用户数据的安全性。

除了边缘计算,CDN还包括负载均衡技术和缓存技术,负载均衡技术可以均匀分配网络流量,避免单个服务器过载,从而提高系统的整体性能,而缓存技术则通过在靠近用户的节点存储常用数据,进一步减少访问延迟。
CDN技术是构建元宇宙不可或缺的一部分,它通过优化内容传输,提升用户体验,确保元宇宙的流畅运行,随着技术的不断进步,我们有理由相信,未来的元宇宙将变得更加丰富多彩,为用户带来前所未有的沉浸式体验。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20