如何搭建CDN并配置Nginx?

CDN搭建与Nginx配置详解
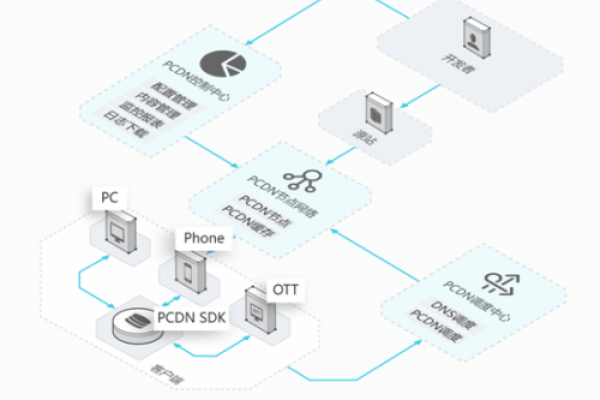
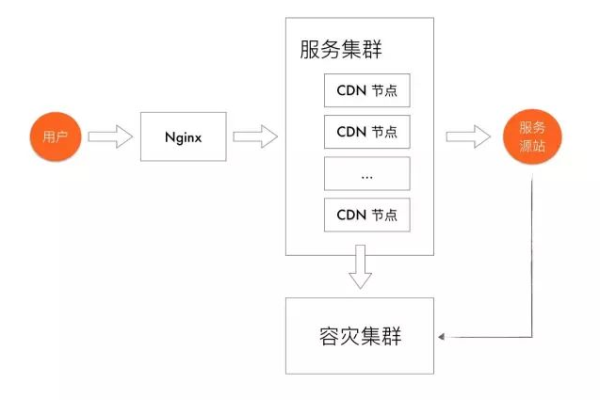
CDN(内容分发网络)是现代互联网架构中不可或缺的一部分,用于加速网站访问速度、减轻服务器负载以及提高网站的可靠性和安全性,通过将静态资源缓存到距离用户更近的节点上,CDN可以显著提升用户体验,本文将详细介绍如何使用Nginx搭建一个简单的CDN系统,并附上相关FAQs和小编有话说部分。
一、选择合适的CDN服务商
选择合适的CDN服务商是成功搭建CDN的第一步,市面上有许多知名的CDN服务商,如Cloudflare、Akamai、AWS CloudFront等,选择时应考虑以下几个因素:
1、地域覆盖范围:确保CDN服务商在目标用户所在的地区有良好的网络覆盖。
2、性能:不同CDN服务商的性能可能有差异,选择一个能够提供高性能服务的供应商。
3、价格:根据预算选择合适的CDN服务商,注意比较不同服务商的收费标准。
4、支持的功能:有些CDN服务商提供高级功能,如DDoS防护、SSL证书等,根据需求选择。
5、服务质量:选择有良好客户支持和服务质量的供应商。
二、配置CDN服务
以Cloudflare为例,配置步骤如下:
1、注册和登录:在选择的CDN服务商官网注册并登录账号。

2、添加域名:在CDN服务商的控制面板中添加你的网站域名。
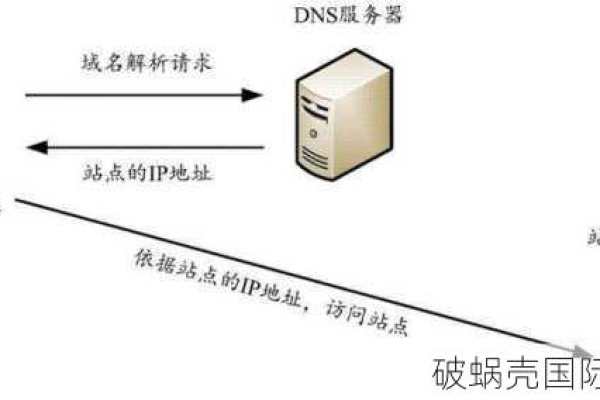
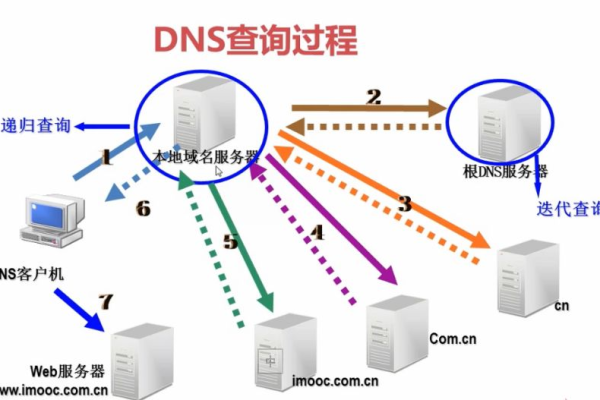
3、配置DNS:将你网站的DNS解析指向CDN服务商提供的服务器地址,这通常需要在你的域名注册商那里进行配置。
4、设置缓存规则:根据需要设置CDN的缓存规则,如缓存时间、缓存对象等。
5、启用SSL:如果你的网站使用HTTPS,需要在CDN服务中启用SSL证书。
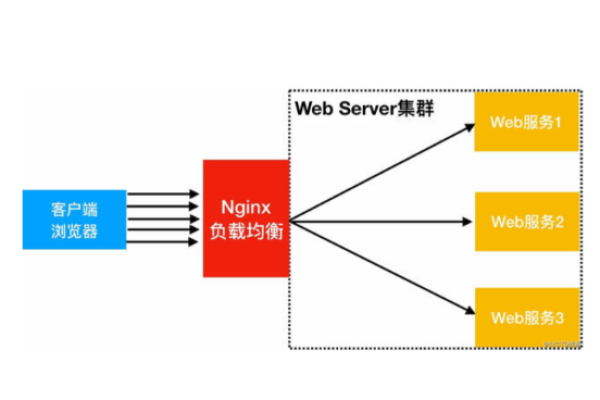
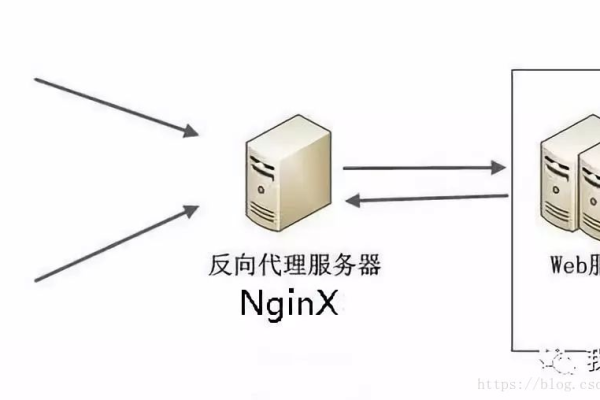
三、在Nginx中进行配置
配置完成后,还需要在你的网站服务器上进行相应的配置,以下是Nginx中配置CDN的基本步骤:
1、安装Nginx:确保你的服务器上已经安装并配置好Nginx。
2、修改Nginx配置文件:在Nginx的配置文件(通常是nginx.conf或sites-available中的某个文件)中添加或修改以下内容:

server {
listen 80;
server_name yourdomain.com;
location / {
proxy_pass http://your_cdn_url;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
# 如果使用HTTPS,还需配置SSL
listen 443 ssl;
ssl_certificate /path/to/ssl_certificate.crt;
ssl_certificate_key /path/to/ssl_certificate_key.key;
} 3、重启Nginx:保存配置文件后,重启Nginx服务以使配置生效:
sudo systemctl restart nginx
四、测试和优化
配置完成后,需要进行测试和优化以确保CDN配置正确且性能最佳,以下是一些测试和优化的步骤:
1、测试网站访问:通过浏览器访问你的网站,检查是否能正常加载内容,并且加载速度是否有提升。
2、检查CDN缓存:使用CDN服务商提供的工具或第三方工具,检查CDN的缓存命中率和缓存效果。
3、优化缓存规则:根据测试结果,调整CDN的缓存规则,以提高缓存命中率和加载速度。
4、监控性能:使用性能监控工具(如Google Analytics、Pingdom等),持续监控网站的性能和用户体验。
5、调整Nginx配置:根据实际需求和测试结果,进一步优化Nginx的配置,如启用Gzip压缩、设置合理的超时等。

五、常见问题与解决方法
1、Q: DNS解析错误怎么办?
A: 检查域名解析设置是否正确,确保指向CDN服务商提供的服务器地址,如果问题依旧存在,可以尝试清除本地DNS缓存或联系域名注册商寻求帮助。
2、Q: SSL证书问题如何解决?
A: 确保在CDN服务和Nginx中都正确配置了SSL证书,如果使用的是免费证书,可以使用Let’s Encrypt;如果是付费证书,请按照提供商的说明进行配置,还要确保证书链完整无误。
六、小编有话说
搭建CDN并不是一件容易的事情,它涉及到多个环节的选择与配置,但只要按照上述步骤一步步来,就能顺利完成,选择合适的CDN服务商至关重要,它将直接影响到你网站的性能和用户体验,持续的测试和优化也是保证CDN效果的关键,希望本文对你有所帮助!

热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01