装维cdn

玩转维 CDN:加速网络世界的幕后英雄
在当今数字化时代,网络速度与稳定性已成为用户体验的关键因素,而内容分发网络(CDN)作为一项关键技术,正发挥着日益重要的作用,维 CDN 凭借其独特优势,在众多领域展现出强大的实力。
一、维 CDN 的基本原理
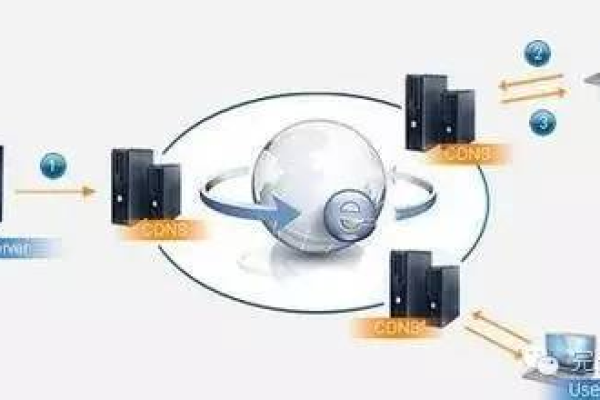
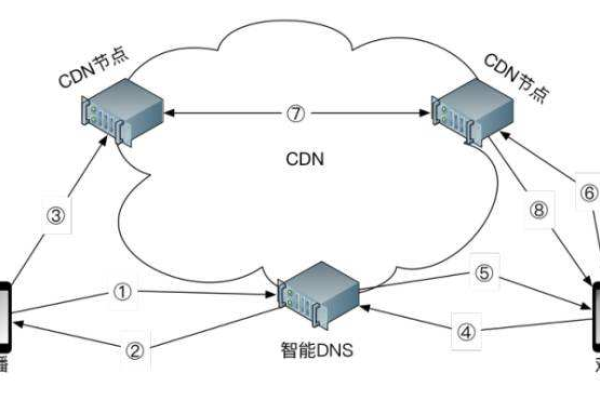
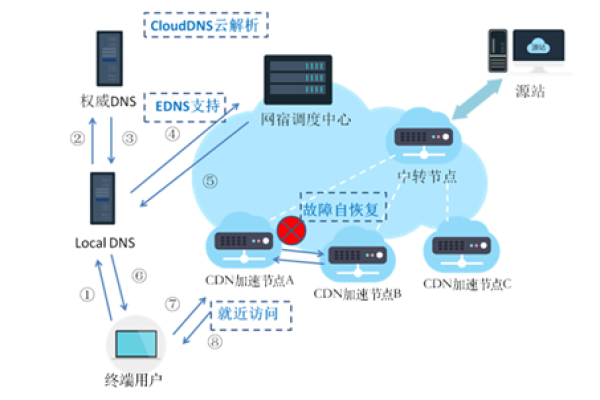
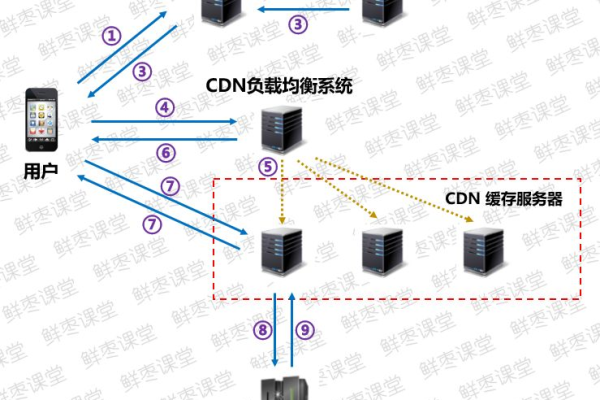
维 CDN 通过在全球各地部署大量的服务器节点,构建起一个庞大的分布式网络,当用户请求某个网络资源时,维 CDN 会根据用户的地理位置、网络状况等因素,智能地将请求定向到距离用户最近且负载较轻的节点上,这些节点缓存了原始资源,能够快速响应用户请求,从而大大缩短了数据传输的时间,提高了访问速度,一个位于北京的用户访问一家电商网站的图片资源,如果该网站使用了维 CDN,那么很可能从位于北京附近机房的节点获取图片,而不是从遥远的服务器源头获取,这样就能瞬间呈现出清晰的商品图片,提升用户浏览体验。
| 用户位置 | 未使用维 CDN 情况 | 使用维 CDN 情况 |
| 北京 | 访问延迟高,图片加载缓慢 | 低延迟,快速加载图片 |
| 上海 | 同上 | 同上 |
| 广州 | 同上 | 同上 |
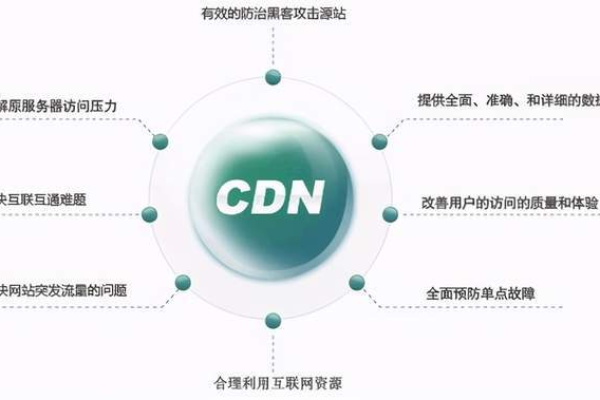
二、维 CDN 的核心优势
1、加速性能卓越:如前所述,通过就近原则提供内容,有效减少数据传输距离和时间,显著提升网页加载速度、视频播放流畅度等,对于在线视频平台而言,这意味着更少的卡顿和缓冲,让观众能够沉浸在流畅的视听享受中。

2、可靠性高:维 CDN 具有冗余架构,即使某个节点出现故障,其他节点仍能正常提供服务,确保内容的持续可用性,这在应对突发流量高峰或网络攻击时尤为重要,保障了网站的稳定运行,避免因单点故障导致服务中断。
3、可扩展性强:随着用户数量和业务的增长,维 CDN 能够轻松添加新的节点和带宽资源,以满足不断变化的需求,无论是新兴的互联网企业还是大型电商平台的业务扩张,维 CDN 都能灵活适应,为其提供稳定的支持。
三、维 CDN 的应用场景
1、网站加速:各类企业官网、新闻门户、社交媒体等网站借助维 CDN,为全球用户提供高速访问体验,提升品牌形象和用户粘性。

2、视频流媒体:视频分享网站、在线教育平台等利用维 CDN 实现高清视频的流畅播放,满足用户随时随地观看视频的需求。
3、游戏行业:在线游戏中的地图、角色模型等资源通过维 CDN 分发,降低游戏延迟,提高游戏的实时性和趣味性。
四、相关问题与解答
问题 1:维 CDN 是如何判断用户地理位置的?

解答:维 CDN 通常通过多种方式判断用户地理位置,一种常见的方法是利用用户的 IP 地址进行地理定位,IP 地址数据库中包含了 IP 地址与地理位置的对应信息,还可以结合用户的网络接入点(如 Wi-Fi 热点信息)、GPS 数据(在移动设备允许的情况下)等进行更精准的定位,以便将用户请求准确地定向到最合适的节点。
问题 2:使用维 CDN 是否会导致内容更新不及时?
解答:一般不会,维 CDN 有完善的缓存更新机制,当源内容发生更新时,源站会通知 CDN 网络,CDN 会依据一定的策略(如 TTL 过期、主动推送等)及时更新各节点上的缓存内容,确保用户获取到的是最新信息,也可以根据内容的重要性和更新频率设置不同的缓存规则,以平衡性能与内容更新的及时性。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22