抓取CDN文件

关于抓取 CDN 文件的详细指南
一、什么是 CDN 文件
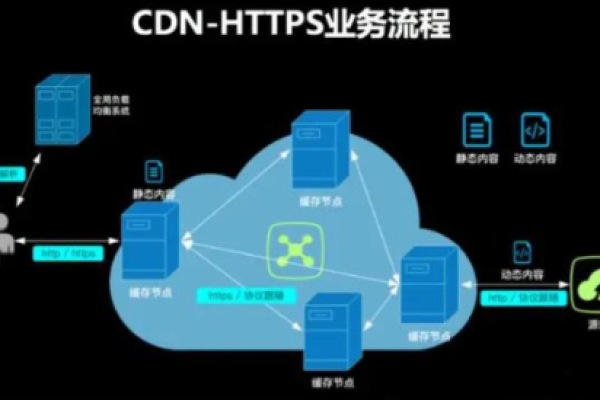
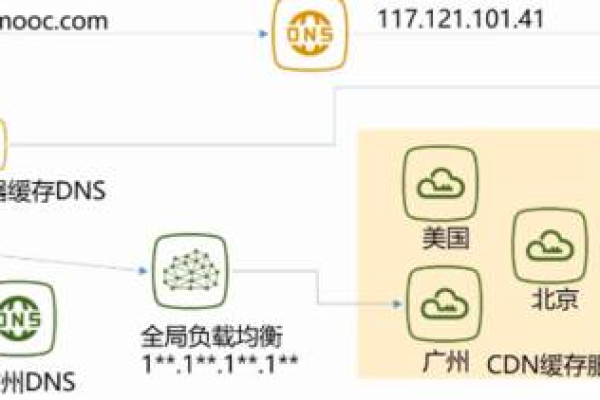
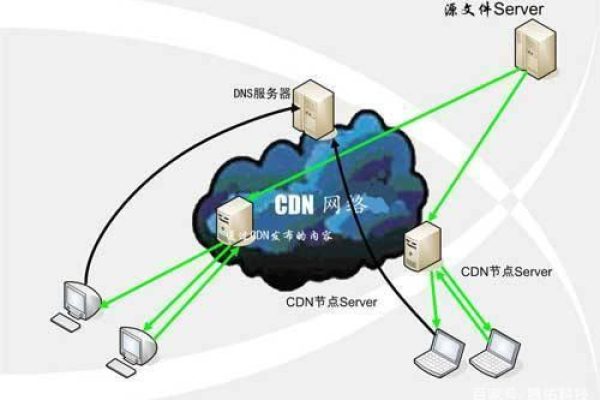
CDN(Content Delivery Network),即内容分发网络,是一种分布式服务器系统,它通过在不同地理位置部署服务器节点,将网站的内容缓存到离用户最近的节点上,从而加速用户对网站的访问速度,提高用户体验,CDN 文件则是指存储在 CDN 节点上的各类资源文件,包括但不限于网页文件(HTML、CSS、JavaScript 等)、图片(JPEG、PNG、GIF 等)、视频(MP4、FLV 等)、音频(MP3、WAV 等)以及其他静态资源文件(如字体文件、图标文件等)。
二、抓取 CDN 文件的常见方法
(一)使用浏览器开发者工具抓取
1、操作步骤:
打开目标网站,在页面上右键点击,选择“检查”或“审查元素”,打开浏览器的开发者工具。
切换到“Network”(网络)选项卡,此时会显示该页面加载过程中的所有网络请求信息,包括各种资源文件的请求。
可以根据资源类型(如 Images、Scripts、Stylesheets 等)筛选出 CDN 文件,也可以直接在搜索框中输入关键词查找特定文件。
找到目标 CDN 文件后,右键点击该文件条目,选择“Open in new tab”(在新标签页中打开)或“Copy link address”(复制链接地址),即可获取该文件的 URL 并进行下载或其他操作。
2、适用场景与优缺点:
适用场景:适用于快速定位和获取单个或少量 CDN 文件,尤其是在进行前端开发调试或分析页面资源加载情况时非常方便。
优点:操作简单直观,无需额外安装软件,能直接在浏览器中完成抓取操作,并且可以实时查看文件的加载状态和相关信息。
缺点:对于大量 CDN 文件的批量抓取效率较低,且无法自动抓取整个网站的 CDN 资源,需要人工逐个筛选和操作。
(二)使用命令行工具 wget 抓取
1、wget 简介:wget 是一个命令行下的网络文件下载工具,支持递归下载、断点续传等功能,可用于抓取网页及其相关的资源文件,包括 CDN 文件。
2、基本语法与参数:
wget [选项] [URL]

常用选项示例:
-r:递归下载,可抓取整个网站或目录下的文件。
-p:只抓取网页及其必需的图片、CSS、JavaScript 等资源,不会深入抓取其他子页面的资源。
-k:转换链接,将下载的文件中的相对链接转换为本地绝对链接,以便在本地浏览时链接能够正常跳转。
-P:指定下载文件保存的目录路径。
3、抓取示例:
若要抓取某个网页的 CDN 图片资源,可以使用命令:wget -r -A.jpg,.png,.gif http://example.com/page(假设该网页上有大量图片资源,此命令将递归下载该页面下所有 jpg、png、gif 格式的图片文件到当前目录)。
若只想抓取网页本身的 HTML 及相关必要资源,方便后续在本地查看完整页面效果,可使用:wget -p http://example.com/index.html。
4、适用场景与优缺点:
适用场景:适合有一定命令行操作基础的用户,对于批量抓取 CDN 文件或特定类型的资源文件较为高效,常用于自动化脚本或服务器端任务中。
优点:功能强大,可通过丰富的参数组合实现灵活的文件抓取策略;支持断点续传,即使下载中断也能从中断处继续下载;可在命令行脚本中集成,便于自动化处理。

缺点:需要一定的学习成本来掌握其命令语法和参数使用方法;对于复杂的网站结构或存在动态加载资源的页面,可能无法完全准确地抓取所有相关 CDN 文件。
(三)使用 Python 爬虫抓取
1、Python 爬虫原理简述:利用 Python 编程语言编写脚本程序,模拟浏览器向目标网站发送 HTTP 请求,解析返回的 HTML 内容,提取其中的 CDN 文件链接,然后根据链接下载相应的文件,常用的库包括requests(用于发送 HTTP 请求)、BeautifulSoup(用于解析 HTML 文档)、os(用于文件操作)等。
2、简单代码示例:
import requests
from bs4 import BeautifulSoup
import os
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
查找所有图片链接
img_tags = soup.find_all('img')
for img in img_tags:
img_url = img.get('src')
if not img_url.startswith('http'):
img_url = url + img_url
img_name = os.path.basename(img_url)
img_data = requests.get(img_url).content
with open(img_name, 'wb') as f:
f.write(img_data)
print(f'Downloaded {img_name}')
3、适用场景与优缺点:
适用场景:适用于有一定编程能力的用户,尤其是需要进行定制化抓取任务或处理复杂网站结构的情况,可以灵活地根据需求编写代码来抓取特定类型的 CDN 文件或满足特定的业务逻辑。
优点:高度可定制,能够适应各种复杂的网站结构和抓取需求;可以利用 Python 强大的库生态系统实现丰富的功能扩展,如数据清洗、存储等;可与其他数据处理流程无缝集成。
缺点:编写和维护代码需要一定的编程知识和技能;对于一些反爬虫机制较强的网站,可能需要额外的技术手段来绕过限制,增加了开发的复杂性。
三、抓取 CDN 文件时需要注意的问题
(一)合法性问题
在抓取 CDN 文件之前,务必确保自己的行为符合法律法规以及目标网站的使用条款,未经授权抓取受版权保护的文件或违反网站的服务协议可能导致法律纠纷或被追究法律责任,一些商业网站明确禁止未经授权的数据抓取行为,如果违反规定可能会面临侵权指控。
(二)反爬虫机制
许多网站为了防止数据被反面抓取或滥用,设置了反爬虫机制,常见的反爬虫手段包括限制 IP 访问频率、检测 User-Agent 头信息、设置验证码验证、识别爬虫特征等,当遇到反爬虫机制时,需要采取相应的应对措施,如使用代理 IP 池来轮换 IP 地址、修改 User-Agent 为常见的浏览器标识、使用验证码识别与破解工具(但需注意合法合规性)或模拟人类操作行为等方式来绕过限制,但前提是不违反法律法规和道德规范。
(三)文件更新与缓存问题
CDN 文件可能会随着源站内容的更新而发生变化,或者由于缓存策略的不同导致不同节点上的文件版本不一致,在抓取 CDN 文件时,需要考虑文件的更新频率以及如何获取最新的文件版本,可以通过设置合适的缓存失效时间、定期重新抓取或与源站进行数据同步等方式来确保获取到最新有效的文件。

四、相关问题与解答
(一)问题:抓取 CDN 文件是否一定会涉及到侵犯版权?
解答:不一定,如果抓取的 CDN 文件是公开可访问且未受到版权保护的公共领域作品,或者在符合合理使用原则(如个人学习、研究、评论等非商业目的且未对原作者权益造成实质性损害)的情况下进行抓取,一般不涉及侵权,但如果抓取受版权保护的商业文件、未经授权的独家内容等用于商业用途或传播盈利,则很可能构成侵权行为,在使用任何抓取方法之前,最好仔细阅读目标网站的版权声明和使用条款,并咨询专业法律意见以确保合法性。
(二)问题:使用 Python 爬虫抓取 CDN 文件时,如何提高抓取效率?
解答:可以从以下几个方面提高 Python 爬虫抓取 CDN 文件的效率:
1、多线程或异步编程:利用 Python 的多线程(如threading 模块)或异步编程(如asyncio 库结合aiohttp 库)技术,同时发起多个请求,提高下载速度,但要注意控制并发数量,避免对目标网站造成过大压力。
2、优化请求头:合理设置请求头中的 User-Agent、Referer 等信息,模拟真实浏览器行为,减少被目标网站识别为爬虫而拒绝访问的概率,可以根据目标网站的响应情况调整请求头参数,提高请求成功率。
3、连接池管理:使用连接池技术(如requests 库中的Session 对象)来复用 HTTP 连接,减少建立连接和关闭连接的开销,提高请求响应速度。
4、数据存储优化:选择合适的数据存储方式,如使用数据库(如 SQLite、MySQL 等)或高效的文件存储格式(如 HDF5 等),提高数据写入和读取效率,在存储大量 CDN 文件时,可以考虑分布式存储系统或云存储服务来提高存储容量和访问速度。

热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22