存储类型的转换

全面解析与应用指南
在计算机科学和数据处理的领域中,存储类型的转换是一个至关重要的概念,它涉及到数据在不同格式和表示方式之间的相互转化,这种转换不仅影响着数据的存储效率,还直接关系到数据处理的准确性和速度,本文将深入探讨存储类型转换的基本原理、常见类型、应用场景以及相关的技术挑战,旨在为读者提供一个全面而详细的理解框架。
一、存储类型转换的基本原理
存储类型转换,简而言之,就是将数据从一种存储格式或类型转换为另一种,这一过程通常涉及到数据的读取、解析、重新编码以及写入新格式等多个步骤,将文本文件中的数据转换为二进制格式,或者将图像文件从一种压缩格式转换为另一种,都是存储类型转换的具体实例。
数据读取与解析
数据读取是转换过程的第一步,它涉及从原始存储介质(如硬盘、内存或网络)中获取数据,解析则是对读取到的数据进行结构化处理,以便后续的转换操作,这一步骤可能包括识别数据类型、分割数据块、解码压缩数据等。
重新编码与格式化
根据目标存储类型的要求,对解析后的数据进行重新编码和格式化,这可能涉及到改变数据的字节序、调整数据结构、应用新的压缩算法等,将ASCII编码的文本转换为UTF-8编码,或者将整数从32位转换为64位表示。
写入新格式
将重新编码和格式化后的数据写入到新的存储介质或文件中,这一步需要确保数据的完整性和一致性,避免在转换过程中出现数据丢失或损坏的情况。
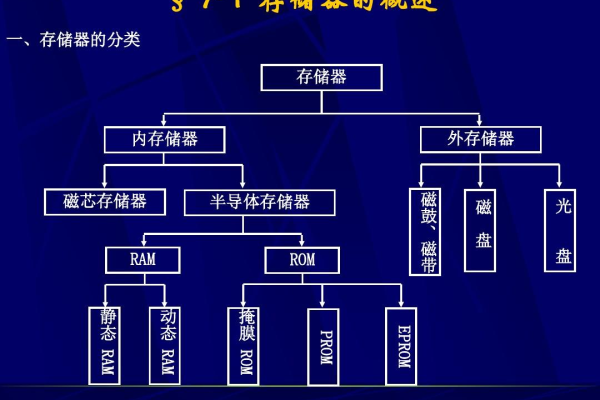
二、常见的存储类型转换
文本与二进制之间的转换
文本文件通常以人类可读的形式存储数据,而二进制文件则以机器可读的形式存储,两者之间的转换广泛应用于配置文件读取、数据序列化等场景,JSON格式的配置文件可以转换为二进制格式以提高读取效率。

图像格式转换
图像文件有多种存储格式,如JPEG、PNG、BMP等,不同格式在压缩比、色彩深度、透明度支持等方面各有优劣,根据具体需求选择合适的图像格式并进行转换是常见的操作,将高分辨率的BMP图像转换为JPEG格式以减小文件大小。
音频与视频格式转换
音频和视频文件也存在多种存储格式,如MP3、WAV、AVI、MP4等,格式转换可以改变文件的编码方式、比特率、分辨率等参数,以满足不同的播放需求或存储限制,将高清视频文件转换为低分辨率版本以便于在线流媒体播放。
数据库数据导出与导入
在数据库管理中,经常需要将数据从一种数据库系统导出到另一种系统,或者从数据库导出到平面文件(如CSV、XML)以供其他应用程序使用,这种转换涉及到SQL查询、数据映射以及文件I/O操作等多个方面。
三、应用场景与技术挑战
应用场景
数据迁移:在系统升级或更换硬件时,需要将旧系统中的数据迁移到新系统。
数据共享:不同应用程序之间需要共享数据时,可能需要进行格式转换以确保兼容性。

性能优化:通过改变数据的存储格式来提高读写速度或减少存储空间占用。
技术挑战
数据一致性:在转换过程中保持数据的一致性和完整性是一个重要挑战,任何错误都可能导致数据丢失或损坏。
性能开销:转换操作通常需要消耗额外的计算资源和时间,特别是在处理大量数据时,如何优化转换算法以提高效率是一个关键问题。
安全性:某些存储类型转换可能涉及到敏感信息的解密或重新加密过程,如何确保这些信息的安全性也是不容忽视的问题。
四、相关问答FAQs
Q1: 为什么需要进行存储类型的转换?

A1: 存储类型的转换是为了适应不同的应用场景和需求,为了提高数据传输效率,可能需要将数据从文本格式转换为二进制格式;或者为了节省存储空间,可能需要将图像从无损格式转换为有损压缩格式,不同的系统或应用程序可能支持不同的存储类型,因此转换也是为了实现数据兼容性和互操作性。
Q2: 在进行存储类型转换时,如何确保数据的安全性和完整性?
A2: 确保数据安全性和完整性的关键措施包括使用可靠的转换工具和算法、实施严格的访问控制和身份验证机制、以及进行定期的数据备份和恢复测试,对于敏感信息的处理,应遵循相关的安全标准和法规要求,如使用加密技术来保护数据传输和存储过程中的安全。
小编有话说
存储类型的转换是数据处理中不可或缺的一环,它涉及到技术的多个方面,并面临着诸多挑战,随着技术的不断进步和应用场景的日益丰富,存储类型转换的技术和方法也将不断发展和完善,作为数据处理的从业者或爱好者,我们应该持续关注这一领域的最新动态和技术进展,不断提升自己的专业技能和知识水平。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22