存储网页的文件夹

在现代互联网浏览和使用过程中,用户经常会遇到需要保存网页以便离线查看或存档的情况,无论是为了工作、学习还是个人兴趣,了解如何存储网页及其相关文件夹变得尤为重要,以下是关于存储网页的文件夹的详细指南:
一、浏览器自带功能
Chrome浏览器
Chrome浏览器提供了简便的方法来保存整个网页。
步骤:
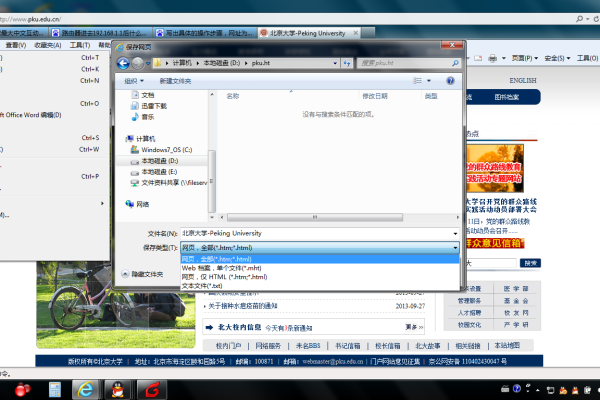
1. 打开你需要保存的网页。
2. 点击浏览器右上角的三点菜单图标。
3. 选择“更多工具” > “另存为”。
4. 在弹出的对话框中,选择保存位置,输入文件名,并选择保存类型(完整页面、HTML 文档等)。
5. 点击“保存”按钮。
存储结构:
HTML文件:包含网页的基本结构和内容。
文件夹:包含所有相关的图片、脚本和样式表。
Firefox浏览器
Firefox也提供了类似Chrome的功能来保存网页。
步骤:
1. 打开目标网页。

2. 点击右键,选择“另存为”。
3. 选择保存位置和文件名,并选择合适的格式(如Web 页面,完整或仅HTML)。
4. 点击“保存”按钮。
存储结构:
HTML文件:包含网页内容。
文件夹:包含所有相关的资源文件。
有时自动保存功能可能无法完全满足需求,尤其是当网页包含动态内容或复杂的布局时,这时,可以手动保存网页的各个部分。
保存HTML文件
步骤:
1. 右键点击网页空白处,选择“查看页面源代码”。
2. 复制所有源代码。

3. 使用文本编辑器(如Notepad++、Sublime Text)创建一个新的HTML文件,粘贴源代码并保存。
保存图片和资源文件
步骤:
1. 右键点击需要保存的图片或其他资源,选择“另存为”。
2. 选择保存位置并命名文件。
三、使用第三方工具
一些第三方工具可以帮助更高效地保存和管理网页内容,HTTrack是一个免费的网站拷贝器,能够递归地下载整个网站。
HTTrack使用步骤:
1. 下载并安装HTTrack。
2. 打开程序,输入项目名称和要保存的网站URL。
3. 配置选项(如深度、镜像链接等)。
4. 点击“开始”按钮开始下载。

四、存储和管理建议
为了更好地管理和查找保存的网页,建议遵循以下最佳实践:
1、分类存储:根据主题或用途将网页分门别类地存储在不同的文件夹中。
2、命名规范:使用有意义的文件名和文件夹名,方便日后搜索和识别。
3、定期备份:定期备份重要网页和文件夹,防止数据丢失。
FAQs
Q1: 如果网页包含动态内容,如何保存?
A1: 对于包含动态内容的网页,可以使用浏览器的开发者工具来捕获所需的数据,在Chrome中,可以通过“检查元素”功能查看和复制动态加载的内容。
Q2: 如何确保保存的网页在没有网络的情况下也能正常查看?
A2: 确保保存了完整的HTML文件和所有相关的资源文件(如图片、CSS和JavaScript文件),这样即使没有网络连接,也可以离线查看网页内容。
小编有话说
存储网页的文件夹不仅仅是一个简单的技术操作,更是对信息管理和知识积累的一种方式,通过合理地保存和管理网页内容,我们可以更好地利用这些资源进行学习和工作,希望本文能帮助你掌握存储网页的技巧,让你的数字生活更加有序和高效。