
上一篇
云硬盘能否支持MySQL数据库进行每日多次备份?
MySQL数据库支持每天多次备份,具体取决于所使用的备份工具和云硬盘服务。大多数云服务提供商都提供定时备份功能,允许用户设置每日多次自动备份。
MySQL 每天备份数据库
在当前数字化时代,数据的重要性不言而喻,为了确保数据的安全性和可靠性,定期备份数据库显得尤为重要,对于 MySQL 数据库而言,每天进行备份不仅可以防止数据丢失,还能在灾难发生时迅速恢复数据,本文将详细讨论 MySQL 每天备份的相关内容,包括云硬盘的支持、备份类型以及如何设置自动备份等。
云硬盘支持每天多次备份吗?
答案:是的,云硬盘可以支持每天多次备份。
云硬盘作为一种高效且可靠的存储解决方案,能够提供灵活的备份频率和多样的备份方式,无论是物理备份还是逻辑备份,云硬盘都能够很好地满足用户的需求,通过合理的配置和策略,用户可以在云硬盘上实现每天多次备份,以确保数据的高可用性和安全性。
备份类型及其特点
MySQL 数据库支持多种备份类型,主要包括以下几种:
1、全量备份:这种备份方式会备份数据库中的所有数据,适用于定期进行全面的数据保存,全量备份通常在非业务高峰期进行,以减少对数据库性能的影响。
2、增量备份:只备份自上次全量备份或增量备份以来发生变化的数据,增量备份的优势在于其备份速度较快,占用空间较小,但需要依赖最近的一次全量备份才能恢复。
3、日志备份:备份数据库的二进制日志文件(binlog),这些日志记录了所有更改数据的 SQL 语句,日志备份有助于将数据恢复到某个特定的时间点。

4、快照备份:通过对存储层磁盘创建快照的方式进行备份,这种方式的备份速度快,相对占用体积小,但不支持下载。
设置自动备份的方法
为了实现每天多次备份,可以通过设置自动备份任务来实现,以下是一些常见的设置方法:
1、使用云服务商提供的自动备份功能:许多云服务商(如阿里云、腾讯云)都提供了自动备份功能,用户可以在云控制台上设置备份计划,指定备份的时间和频率。
2、使用第三方备份工具:市面上有许多第三方备份工具(如 Percona XtraBackup、mydumper 等)也支持自动备份功能,用户可以根据具体需求选择合适的工具,并配置相应的备份策略。
3、编写脚本进行自动化备份:对于有编程能力的用户,可以编写脚本(如 shell 脚本、Python 脚本等)来实现自动化备份,脚本可以定时运行,根据预设的备份策略执行相应的备份操作。
注意事项
在进行每天多次备份时,需要注意以下几点:
1、备份时间的选择:应尽量选择在业务低峰期进行备份,以减少对数据库性能的影响。
2、备份数据的存储和管理:应合理规划备份数据的存储位置和管理方式,确保备份数据的安全和可访问性。
3、定期测试恢复:应定期进行恢复测试,以验证备份数据的完整性和可用性。
FAQs
Q1: 云硬盘支持哪些类型的数据库备份?
A1: 云硬盘支持多种类型的数据库备份,包括物理备份、逻辑备份和快照备份等,具体支持的备份类型可能因不同的云服务商和数据库版本而有所不同。
Q2: 如何设置 MySQL 数据库的自动备份?
A2: 设置 MySQL 数据库的自动备份可以通过多种方式实现,包括使用云服务商提供的自动备份功能、第三方备份工具以及编写脚本进行自动化备份等,具体设置方法应根据用户的实际需求和环境条件来选择。
通过以上内容可以看出,MySQL 每天备份数据库是一项重要且必要的工作,通过合理选择备份类型和设置自动备份策略,可以确保数据的安全性和可靠性,云硬盘作为一种高效的存储解决方案,能够很好地支持每天多次备份的需求,希望本文能为您在 MySQL 数据库备份方面提供有益的参考和帮助。
相关文章
-

cloudinit 硬盘多次分区_云硬盘支持每天多次备份吗
-
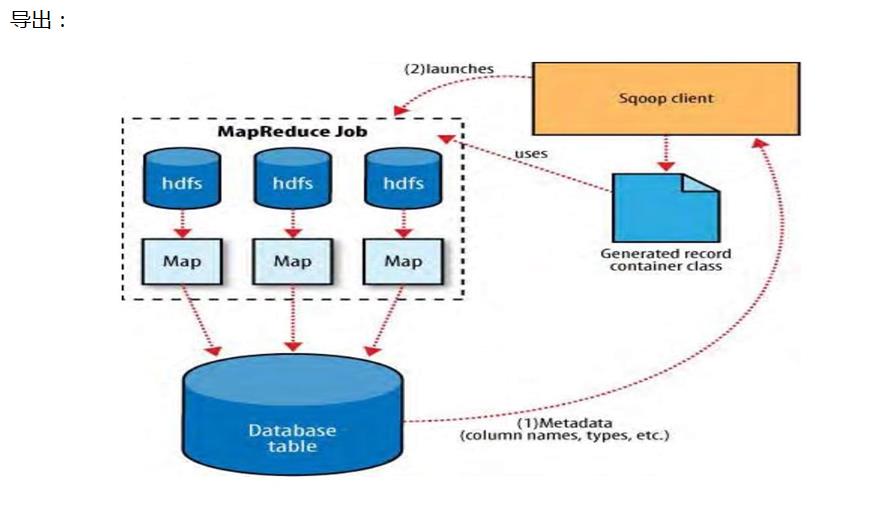
云硬盘服务是否支持执行多次MapReduce操作的每日备份?
-
Justhost主机能否支持Magento呢? (justhost主机支持magento吗)
-

mysql数据库代码_Mysql数据库这篇文章可能涉及MySQL数据库的编程、管理或优化等方面的内容。根据这些信息,我们可以为文章生成一个原创的疑问句标题,例如,,如何编写高效的MySQL数据库代码以提升性能?,不仅提出了一个问题,而且暗示了文章内容可能包含关于编写高效MySQL代码和提升数据库性能的技巧与建议。
-
每日小结30字,每日小结已更新(每日小结30字,每日小结已更新怎么写)
-

MySQL与MariaDB是否兼容?云数据库RDS for MySQL能否支持MariaDB?
-

如何利用GaussDB(for MySQL)进行每日数据库拆分操作?
-

RDS for MySQL是否支持MySQL数据库的版本升级?








