如何快速使用快捷键关闭Win8电脑?

在Windows 8操作系统中,关机快捷键是用户在使用电脑时不可或缺的功能之一,不仅因为它能让用户迅速地将电脑转入休眠或关闭状态,节省时间和电力消耗,还因为它能在紧急情况下迅速切断电源,保护数据安全,下面将详细介绍多种适用于Windows 8的关机快捷方式:
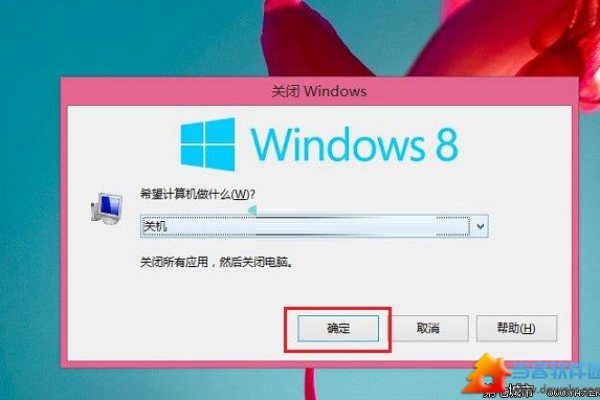
1、标准Charm Bar关机
操作步骤:将鼠标移至屏幕右侧,激活Charm Bar,选择“设置”后点击“电源”图标,最后选取“关机”,这是Windows 8引入的新特性,适合触摸屏设备用户。
特点:直观且易于记忆,结合了Windows 8特有的侧边栏操作,为平板用户设计。
2、桌面右键“开始菜单”
操作步骤:在桌面上右击,选择“开始菜单”选项,再选择关机或重启,这一方法模拟了传统开始菜单的操作,适合习惯传统桌面操作的用户。
特点:简单明了,适用于桌面环境,避免了完全依赖触控屏的操作。
3、快捷键Alt+F4
操作步骤:在当前活动的窗口按Alt+F4键,弹出关闭程序对话框,选择关机或注销,这一方法可以快速关闭当前运行的程序并返回桌面。
特点:快速方便,适用于需要频繁切换应用程序和关闭程序的场景。
4、纯键盘操作

操作步骤:按Win键打开开始屏幕,借助Tab和箭头键导航至“关机”选项,按Enter键确认,这种方式无需使用鼠标。
特点:全程键盘操作,适合鼠标损坏或不便于使用的情况。
5、锁屏快捷方式关机
操作步骤:按下Ctrl+Alt+Del键,选择锁屏或关机,这一方法可以在不登录系统的情况下执行安全关机。
特点:安全性高,适合于需要维护或保护隐私的场合。
6、按钮关机
操作步骤:直接按下电脑的物理电源键,直到系统提示关机为止,这种方法简单粗暴但有效。
特点:最直接快速的关闭电脑方式,但可能会对硬件造成一定压力。

7、快捷方式关机
操作步骤:创建关机快捷方式于桌面,双击即可执行关机,这对于不熟悉快捷键的用户非常友好。
特点:简易操作,特别适合新手或是对电脑不太熟悉的用户。
8、Win+I快捷键
操作步骤:按下Win+I键,进入系统设置,然后选择电源按钮关机,这一方法适合熟练用户,操作速度快。
特点:高效便捷,结合Win键的操作符合微软操作系统的设计哲学。
Windows 8提供了多种关机快捷方式以适应不同用户的需求,从侧面Charm Bar到传统的桌面右键,再到一系列键盘快捷键组合,每一种方法都有其独到之处,旨在提升用户的便利性和效率,选择合适的关机方法,不仅能够节约时间、提高使用效率,还能在必要时保护电脑硬件和数据的安全。
相关问答FAQs

1. 为什么Windows 8取消了传统的开始菜单?
Windows 8旨在打造一种全新的用户体验,更加注重触控操作和简约风格,取消传统开始菜单是为了配合Metro UI(现称为Modern UI),使界面更加现代化和适合触控设备。
2. 如何创建桌面关机快捷方式?
右键点击桌面空白处,选择新建快捷方式;输入shutdown.exe /s /t 0命令作为快捷方式的目标位置;点击下一步,给快捷方式命名(如“关机”),然后点击完成,这样便创建了一个双击即可执行关机操作的快捷方式。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/5321.html