如何在MongoDB中实现秒级监控设置?

mongodbmmsautomationagent。这是一个官方提供的代理工具,可以收集MongoDB的性能数据并将其发送到Monitoring Service。具体步骤如下:,, 1.1. 下载并安装
mongodbmmsautomationagent。请根据您的操作系统选择相应的版本。,, 1.2. 编辑
/etc/mongodbmms/automationagent.conf文件,添加以下内容:,, “
, {, "monitoringServiceUrl": "https://cloud.mongodb.com/api/automation/agent/monitoring",, "groupID": "",, "accessKey": "", }, `
,, 请将
和
替换为您在MongoDB Atlas中创建的相应值。,, 1.3. 重启mongodbmmsautomationagent`服务以应用更改。,,2. 在MongoDB Atlas控制台中,创建一个集群并将您的实例添加到该集群。您可以在Atlas中查看实时性能数据和警报。,,通过以上步骤,您可以实现对MongoDB的秒级
监控。
MongoDB秒级监控设置指南
监控系统的重要性
在现代数据库管理中,监控系统扮演着至关重要的角色,它不仅帮助运维人员及时发现和解决问题,还能为业务决策提供数据支持,一个优秀的监控系统应具备以下三个关键要素:
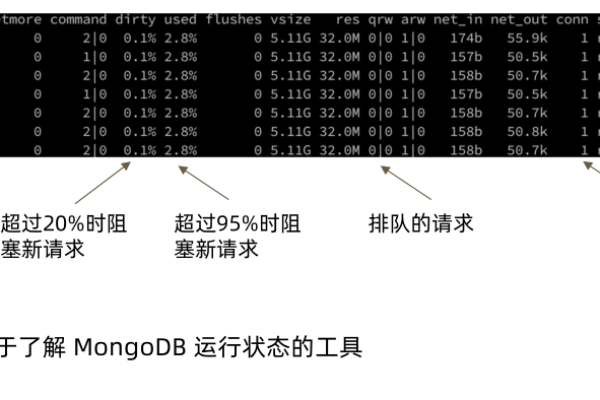
1、监控粒度:指监控的时间间隔,目前很多系统只能做到分钟级或半分钟级监控。
2、监控指标完整性:确保所有重要指标都被采集,避免因漏采关键指标而导致故障无法定位。
3、监控实时性:能够即时反映系统状态,帮助快速响应和处理问题。
秒级监控的优势
阿里云自研的秒级监控系统Inspector,能够实现1秒1点的真秒级监控粒度,全量指标采集且无一疏漏,甚至可以自动采集未曾出现的指标,并实时展示数据,这种监控方式让数据库的任何抖动都无处遁形,给予DBA足够全面的信息,以便第一时间知道故障的发生和恢复。

设置秒级监控的步骤
1、登录阿里云控制台:使用您的阿里云账号登录到控制台。
2、选择MongoDB实例:在云数据库产品列表中找到并选择您要监控的MongoDB实例。
3、开启秒级监控:进入实例详情页面后,找到“监控与告警”选项,点击开启秒级监控功能。
4、配置监控项:根据业务需求,配置需要监控的具体项,如CPU使用率、内存使用情况、磁盘I/O等。
5、设置告警规则:为不同的监控项设置相应的告警阈值和通知方式,确保在出现问题时能及时收到通知。

6、查看监控数据:开启监控后,可以在“监控图表”中查看实时数据和历史记录。
案例分析
案例1:某线上业务使用MongoDB副本集进行读写分离,突然大量读请求超时,通过Inspector发现从库延迟异常飙高,进一步排查发现是由于cache使用率过高导致的evict操作频繁,最终通过限流数据迁移job和增大cache解决了问题。
案例2:某使用分片集群的业务出现访问超时,通过Inspector发现是锁队列过高导致,排查后发现是由于鉴权命令激增引起的全局锁队列飙升,通过减少客户端连接数解决了问题。
这些案例展示了秒级监控在快速定位和解决问题中的重要作用。
常见问题解答
1、问:什么是秒级监控?

答:秒级监控是一种监控系统,其监控粒度达到每秒一次,能够实时反映系统状态,帮助快速响应和处理问题。
2、问:如何设置MongoDB的秒级监控?
答:登录阿里云控制台,选择MongoDB实例,开启秒级监控功能,配置监控项和告警规则,即可完成设置。
通过合理设置和使用秒级监控,可以显著提升MongoDB数据库的稳定性和可靠性,为业务的平稳运行提供有力保障。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/5107.html