
上一篇
如何在Python中导入机器学习包以实现端到端的机器学习场景?
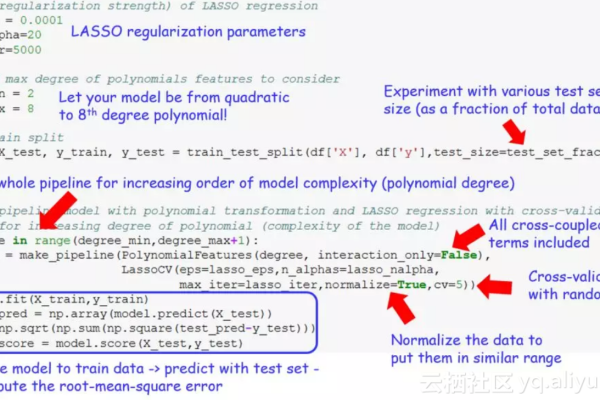
在Python中,导入机器学习库通常涉及使用 import语句加载所需的库或模块。要导入scikitlearn库,可以使用以下代码:,,“ python,from sklearn import svm,“,,这将导入scikitlearn库中的支持向量机(SVM)模块。
在当今时代,机器学习已经成为数据分析和人工智能领域不可或缺的一部分,Python,作为一门广泛应用于科学计算和数据分析的编程语言,拥有多个强大的机器学习库支持各类学习任务,本文将详细介绍如何在Python中导入和使用机器学习包,以及如何应用这些工具包实现端到端的机器学习场景。

导包基础与选择
Python中最常用的机器学习包包括Scikitlearn、PyBrain等,Scikitlearn是基于NumPy、SciPy和matplotlib的开源机器学习库,它提供了一系列的算法,涵盖了聚类、回归、分类、降维和模型选择等多个方面,而PyBrain则是一个目标在于提供灵活、易于使用的同时又不失强大功能的机器学习库。
Scikitlearn的主要功能
1、数据预处理:包括数据清洗、特征工程等功能,为机器学习模型的训练准备数据。
2、特征工程工具:如维度缩减和特征选择,帮助从原始数据中提取对模型训练最有用的特征。
3、模型选择:通过交叉验证等方法评估不同模型的性能,辅助用户选择最合适的模型。
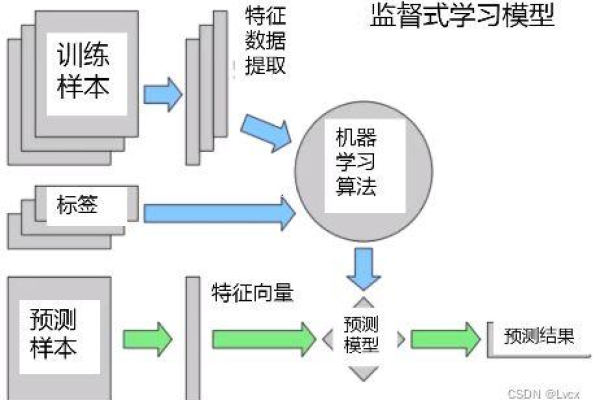
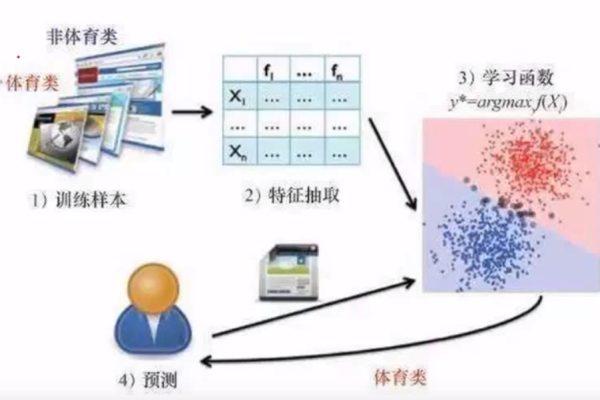
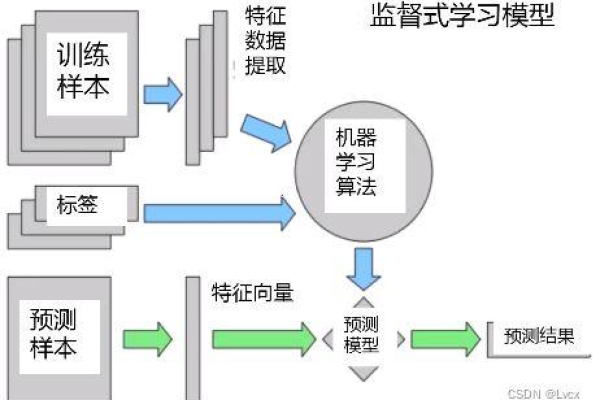
端到端机器学习场景实现
数据收集与预处理
任何机器学习项目的第一步都是数据收集,数据可以来源于公开数据集、通过API获取或是直接从数据库中抽取,数据需要经过预处理阶段,这通常包括数据清洗(处理缺失值和异常值)、数据转换(如归一化或标准化)以及特征选择等步骤。
模型训练
选择合适的机器学习模型是关键步骤之一,Scikitlearn提供了丰富的模型选择,如线性模型、决策树、集成方法等,每种模型都有其适用的场景和优缺点,根据具体问题选择合适的模型至关重要,模型训练涉及将处理好的数据输入模型,并让模型学习数据中的模式。
结果评估与优化
模型训练完成后,下一步是通过测试数据集来评估模型性能,常用的评估指标包括准确率、召回率、F1分数等,还需要对模型进行调优,这可能包括调整模型参数、使用不同的模型或改变数据预处理方式等。
至此,我们已经了Python中导入机器学习包的基本过程以及如何使用这些包实现端到端的机器学习应用场景。
相关问答FAQs
Q1: Scikitlearn和其他机器学习库相比有什么优势?
Q1回答:Scikitlearn最大的优势在于其综合性和易用性,它几乎为所有的经典机器学习任务提供了工具,从数据预处理到模型选择,再到结果评估,形成了一个相对完整的生态系统,Scikitlearn的文档非常全面,社区活跃,对于初学者和研究人员非常友好。
Q2: 在实际应用中,如何选择合适的机器学习模型?
Q2回答:选择合适的机器学习模型依赖于多种因素,包括数据的特性(如特征数量和类型)、问题的类型(分类、回归或聚类等)、以及项目的具体需求(如预测准确性、模型解释性等),我们会从简单的模型开始,如线性回归或逻辑回归,然后根据性能逐步尝试更复杂的模型,利用交叉验证等技术可以帮助我们评估不同模型在独立数据集上的表现,从而做出更加合理的选择。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/49024.html
相关文章
-
如何利用Python的机器学习包实现端到端的机器学习场景?
-
如何利用Python机器学习包实现端到端的机器学习场景?
-
如何在Python中利用机器学习库实现端到端的机器学习场景?
-

如何利用Python机器学习相关库实现端到端的机器学习场景?
-
Python机器学习微盘项目,如何实现端到端的机器学习场景?
-
如何在MATLAB机器学习工具箱中实现端到端的机器学习场景?
-
mstlab机器学习如何实现端到端的机器学习场景?
-
如何实现端到端的机器学习场景在大规模机器学习概论中?
-
如何实现端到端的机器学习项目,Python 机器学习步骤详解?
-
如何在MySQL中实现端到端的机器学习场景?
-
如何实现Python中的机器学习端到端场景?
-
如何在Python中实现机器学习的端到端场景?
-
如何实现模型融合以优化端到端的机器学习场景?
-
如何将Python机器学习项目从开发到上线实现端到端场景?
-
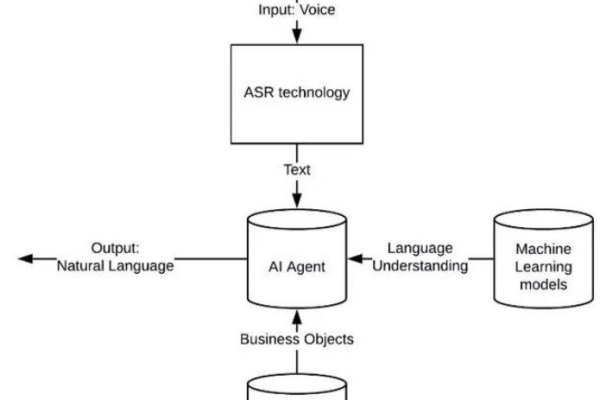
如何在Python中实现Kaggle机器学习端到端场景的完整流程?
-
如何利用Python实现机器学习端到端的完整场景?
-
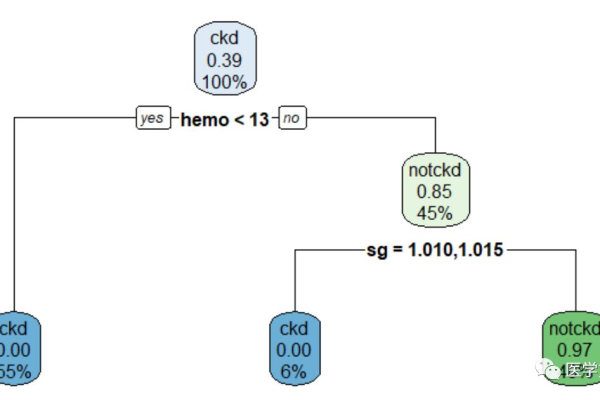
如何在MATLAB中使用决策树进行端到端的机器学习场景构建?
-
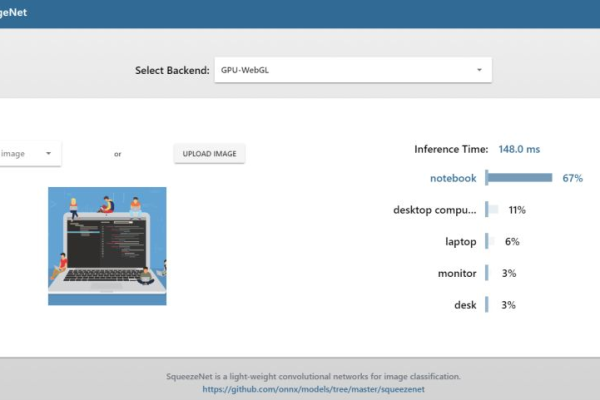
如何端到端地安装Python机器学习包?
-
如何在DART机器学习中实现端到端的应用场景?
-
python 机器学习 用例_机器学习端到端场景