如何优化服务器配置参数以提高系统性能?

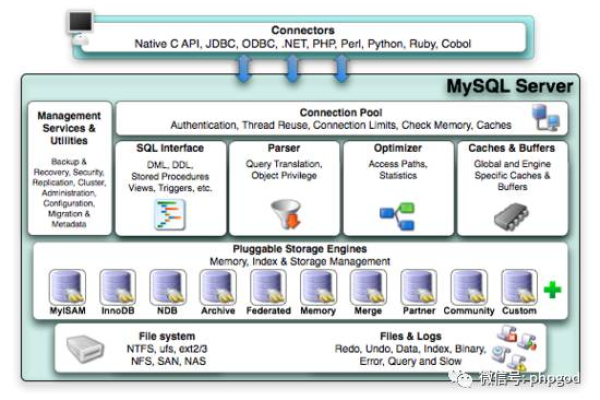
在当今数字化时代,服务器扮演着数据存储和处理的关键角色,选择合适的服务器配置对于确保业务连续性、优化性能和成本控制至关重要,本文将详细介绍服务器配置的各种参数,并提供一些选择建议,以帮助读者根据自身需求做出合适的选择。
CPU(中央处理器)
CPU是服务器的“大脑”,负责处理所有计算任务,CPU的类型、主频和核心数量直接影响服务器的性能,目前市面上常见的CPU品牌有Intel和AMD,其中Intel的Xeon系列和AMD的EPYC系列是专为服务器设计的高性能处理器,选择合适的CPU时,应考虑其核心数、线程数、主频以及热设计功耗(TDP),对于高负载的数据处理任务,多核处理器能提供更好的并行处理能力。
内存(RAM)
服务器的内存影响其能够同时处理的任务数量和速度,内存越大,服务器能够更快地处理更多并发请求,内存的选择应根据服务器的预期用途来决定,数据库服务器和应用程序服务器通常需要较大的内存以支持高速缓存和数据处理,当前市场上的服务器内存通常以GB或TB为单位,常见的配置从8GB到数TB不等。
硬盘(Storage)
硬盘是存储数据的主要设备,分为HDD(硬盘驱动器)和SSD(固态硬盘),SSD提供更快的数据读写速度,适用于对速度要求高的应用,如数据库和实时数据处理,而HDD则因其成本较低且容量较大,适合用于存储不频繁访问的数据,在选择硬盘时,除了考虑类型外,还应考虑容量和接口类型(如SATA、SAS或NVMe)。

网络接口(Network Interface)
网络接口,即网卡,是服务器与外界通信的桥梁,它直接影响数据的输入输出速度,网卡的选择应根据网络环境而定,如1GbE、10GbE或更高速率的网络接口卡,对于需要处理大量网络请求的应用,如视频流服务或大型在线游戏,高速网卡是必须的。
其他重要参数
电源供应:服务器的稳定运行离不开可靠的电源系统,具有冗余电源的配置可以在一个电源失败时仍保持运行,从而提高系统的可靠性。
散热系统:强大的散热系统可以保证服务器在高负载下也能稳定工作,不同的散热解决方案包括风扇冷却、水冷或液冷系统等。
主板平台:主板决定了服务器可以搭载哪些硬件,支持何种扩展功能,选择时应考虑其支持的CPU类型、内存容量及扩展槽等。

选择建议
在选择合适的服务器配置时,首先明确业务需求是关键,不同的应用类型(如Web服务、数据库管理、数据分析等)对硬件的需求不同,考虑到成本和技术升级的可能性,选择可扩展性强的配置也是明智之举,预留足够的内存插槽和硬盘接口可以在将来轻松升级。
服务器配置的选择是一个涉及多方面因素的决策过程,理想的配置应能满足当前的业务需求,同时具备未来升级和扩展的可能,通过了解每个组件的作用和性能指标,可以更有针对性地选择适合自己需求的服务器配置。
FAQs
Q1: 如何判断服务器配置是否满足我的需求?
判断服务器配置是否满足需求,首先需要评估应用的类型和预期的用户负载,对于高并发访问的应用,需要高性能的CPU和大量的内存;对于数据密集型的应用,则需要大容量和高速的存储解决方案,考虑到可能的业务增长,选择具有一定前瞻性的配置也是必要的。

Q2: 如何优化服务器配置以降低成本?
优化服务器配置以降低成本可以从以下几个方面考虑:选择能效比较高的硬件减少电力消耗;根据实际需求合理配置内存和存储空间,避免过度配置;采用虚拟化技术提高硬件资源的利用率;及时更新维护硬件设备,避免因老旧设备导致的额外损失。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/48776.html