DNS域名服务器是如何确保互联网上网站的正确解析的?

DNS域名服务器是互联网中不可或缺的一部分,它负责将人类可读的域名翻译成机器可读的IP地址,这一过程被称为域名解析,是人们能够通过易于记忆的名称来访问网站的关键步骤。
DNS域名服务器的基本作用是将用户输入的域名转换为相应的IP地址,这一转换过程至关重要,因为虽然域名如www.example.com便于人类记忆,但网络中的设备却是通过IP地址来识别和通信的,DNS系统的设计保证了这一转换过程快速而有效,确保了用户可以顺畅地访问互联网资源。
DNS服务依托于分布式数据库系统,这些数据库分布在全球各地的DNS服务器上,这种分布式结构使得DNS服务具有很高的可用性和冗余性,即使某些服务器发生故障,其他的服务器也能接管任务继续提供服务,这种结构还支持对DNS查询的本地化处理,加快了域名解析的速度和效率。
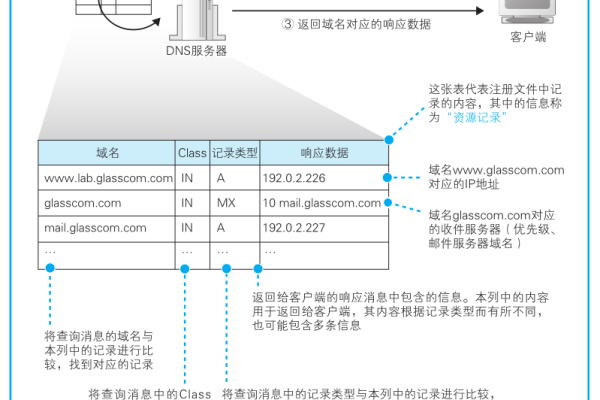
DNS域名解析的过程涉及多个步骤,当用户在浏览器中输入一个域名时,浏览器会向最初接触的DNS服务器发起请求,通常是本地DNS服务器,如果该服务器有对应的IP地址缓存,它会直接响应请求;如果没有,则会向上级或根DNS服务器查询,根DNS服务器会指导请求至相应的顶级域服务器,并最终找到存有目标IP地址的权威DNS服务器,得到IP地址后,该信息会返回给用户的浏览器,并最终加载网页。
DNS服务器的类型主要有根DNS服务器、顶级域DNS服务器、权限服务器和本地DNS服务器,根DNS服务器是整个DNS系统的核心,负责管理和指导全球的域名解析,顶级域服务器则管理如.com、.org等特定的顶级域名,权限服务器通常由域名的拥有者维护,存储着特定域名的地址信息,本地DNS服务器一般由ISP维护,靠近用户地理位置,提供快速的初次解析和缓存服务。

随着互联网的发展,DNS服务也面临各种挑战和优化需求,为了提高解析速度和数据安全,引入了DNS加密(DNSSEC)技术,为了应对DDoS攻击,采用了任播路由技术来分散请求流量,还有针对隐私保护的DNS over HTTPS(DoH)技术,通过加密数据保护用户隐私。
在实际操作中,合理配置DNS设置可以有效提升网络速度和安全性,用户可以选择信誉好的DNS服务提供商,如Google DNS或Cloudflare DNS, 以获得更快更稳定的上网体验,定期检查和更新DNS设置也是保持网络顺畅的重要步骤。
DNS域名服务器是互联网中至关重要的基础设施之一,它通过将人类友好的域名转换为机器可读的IP地址,极大地方便了人们的网络使用,了解其工作原理和挑战有助于更好地利用这一系统,同时采取适当的措施保护个人和企业的网络信息安全。
FAQs

1. 如何检查我的DNS服务器设置是否正确?
可以通过在命令行中输入nslookup www.example.com(将www.example.com替换为任意网站)来查看当前所使用的DNS服务器是否能正确解析域名,如果显示了正确的IP地址,则DNS设置是正确的。
2. 更改DNS设置有什么潜在风险吗?
更改DNS设置一般来说是安全的,但需要确保使用的是可靠的DNS服务提供商,不建议随意使用未知的DNS服务器,这可能导致网络速度变慢或中间人攻击等安全问题。

本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/46080.html
相关文章
-

福建60g高防DNS解析的性能如何?,提出了一个具体的问题,即关于福建地区60克高防DNS解析的性能表现。这可以吸引读者的注意力,并引导他们阅读文章以了解更多相关信息。
-
dns域名服务器如何助力互联网连接?
-
DNS域名服务器如何成为我们接入互联网的核心枢纽?
-

dns服务器是如何帮助互联网用户找到网站的?
-
根域名服务器是如何运作的?探索互联网基础设施的核心
-
福建30g高防DNS解析如何选择?,全面解析与选购指南,了解高防DNS基本概念,什么是高防DNS,高防DNS工作原理,高防DNS重要性,评估自身需求,确定网站流量规模,分析潜在攻击类型,预算与成本考量,选择合适服务提供商,服务商资质与信誉,技术支持与服务响应,客户案例与口碑,比较不同方案,功能与性能对比,价格与性价比分析,用户评价与反馈收集,实施与监控,配置与部署流程,日常维护与管理,安全监控与应急响应,归纳与建议,常见问题解答,未来发展趋势预测,个性化建议提供
-
如何正确解析网上注册的域名?
-
一个关于福建地区200g高防DNS解析的疑问句标题,,福建200G高防DNS解析,如何实现高效防护与快速访问?
-
如何正确解绑互联网网关与全域弹性公网IP?
