域名一口价真的不能讨价还价吗?

域名一口价通常不可谈价,但具体取决于卖家和平台政策。
域名一口价是否可以谈价格取决于卖家的策略和意愿。
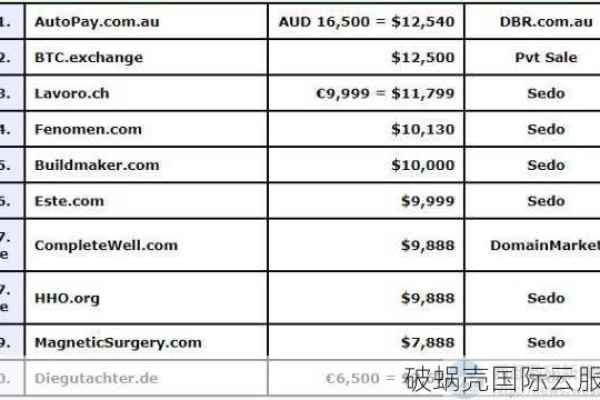
一口价域名是卖家设置的一个固定售价,如果买家接受这个价格并出价,交易就会立即成交,这种交易方式简化了买卖过程,提高了效率,这并不意味着价格完全不可谈,是否能够谈价格主要取决于卖家的态度,一些卖家可能会为了快速完成交易而愿意进行一定程度的让步,尽管这种情况并不普遍。

在实际操作中,买家可以尝试通过电话、邮件或专业的域名交易平台与卖家沟通,探讨是否有调整价格的可能性,需要注意的是,即使卖家同意调整价格,幅度通常也不会很大。

虽然一口价域名的设定是为了简化交易过程,但在某些情况下,买家仍有可能与卖家协商价格,不过,这种可能性并不高,买家在购买时应该做好全面的考虑和准备。
以上就是关于“域名一口价可以谈价格吗”的问题,朋友们可以点击主页了解更多内容,希望可以够帮助大家!






热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22