如何在DedeCMS后台实现全文搜索功能?

Dedecms后台全文搜索功能可以帮助用户快速找到网站中的内容。
Dedecms后台全文搜索功能允许用户在网站后台对文章的全文内容进行搜索,而不仅仅是标题,这一功能对于需要快速定位文章内容的管理员来说非常有用,以下是实现Dedecms后台全文搜索的步骤:
操作步骤
<form action="/plus/advancedsearch.php" method="post"><div class="form"><h4>搜索</h4><input name="mid" value="1" type="hidden"><input name="dopost" value="search" type="hidden">关键词:<input name="q" type="text"><input name="submit" value="开始全文搜索" type="submit"></div></form>
| 步骤 | 描述 |
| 1 | 登录Dedecms后台。 |
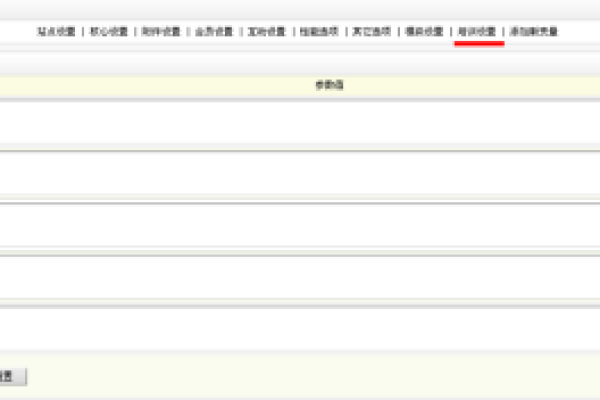
| 2 | 进入“核心”菜单。 |
| 3 | 选择“频道模型”。 |
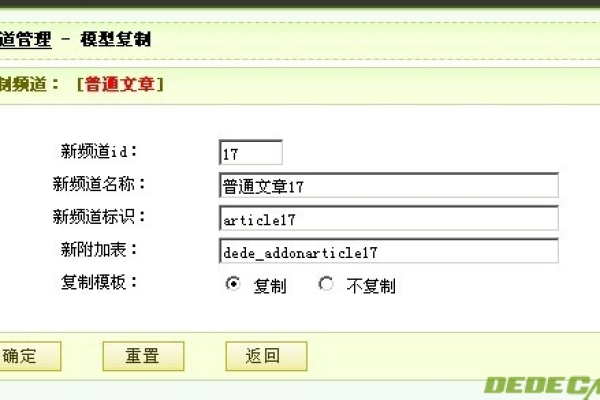
| 4 | 进入“内容模型管理”。 |
| 5 | 选择“普通文章”。 |
| 6 | 点击后面的放大镜标志(这是最重要的一步)。 |
| 7 | 在附件表中,可以看到可供自定义搜索的字段,这些字段是程序根据字段类型自动生成的,将“文章内容”前的选项打勾。 |
| 8 | 此时虽然修改了搜索字段,但还未完全完成,接下来需要修改模板代码。 |
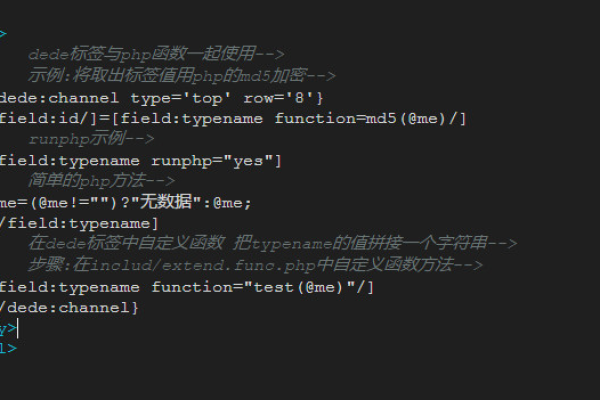
| 9 | 打开模板文件head.htm。 |
| 10 | 将其中的搜索代码替换为以下代码: |
| 11 | 更新网站后,即可发现搜索数据有了质的飞跃。 |
注意事项
1、效率问题:全文搜索可能会降低网站的响应速度,特别是在访问量或搜索量较大时,如果网站规模较大,建议谨慎使用全文搜索功能。

2、用户体验:如果需要频繁使用全文搜索功能,可能说明网站的用户体验有待优化,可以考虑通过百度站长工具申请搜索服务来改善用户体验。
常见问题解答
为什么修改后全文搜索功能仍然不生效?

可能是由于缓存问题导致的,请尝试清除浏览器缓存或服务器缓存后再试,确保模板文件已正确上传并覆盖了旧文件。
全文搜索是否会影响网站性能?
会的,全文搜索通常会增加数据库查询的复杂度和时间,从而可能影响网站的整体性能,在使用全文搜索功能时,应考虑其对网站性能的影响,并采取相应的优化措施,如合理设置缓存、优化数据库查询等。

通过以上步骤,您可以在Dedecms后台实现全文搜索功能,从而更便捷地管理和查找网站内容。

热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22