上一篇
如何利用Python自动登录12306网站并处理验证码完成购票流程?
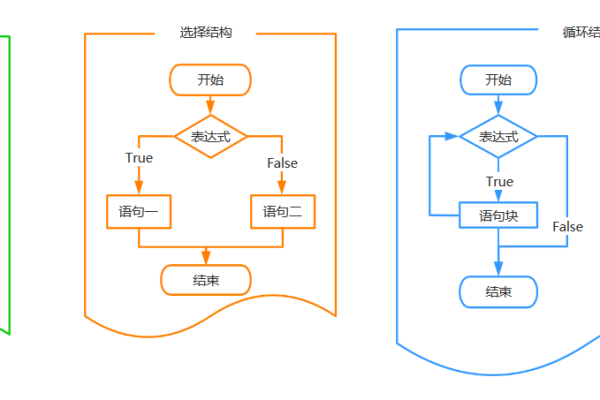
要实现自动登录12306并自动点击验证码,可以使用Python的第三方库如 requests进行网络请求, BeautifulSoup解析网页,以及 pytesseract识别 验证码。但请注意,这可能违反 12306的使用协议,且验证码识别率可能不高。
自动识别12306验证码,python实现登录12306. 使用开源的OCR库Tesseract进行验证码图片的文字识别,并利用requests库发送post请求完成登录操作。

2018年5月27日 — 通过Python实现自动登录12306并自动点击验证码完成登录. 主要介绍如何使用Python + Selenium + Tesseractocr库实现自动登录12306网站,并自动识别和点击验证码.
对于希望使用Python实现自动登录12306并自动点击验证码的需求,可以采用多种技术和方法来实现,下面将详细介绍各种实现方式,并提供必要的代码示例:
1、使用Selenium模拟浏览器操作
模拟用户登录:Selenium是一个用于自动化Web浏览器操作的工具,能模拟真人的行为,如自动填写表单、点击按钮等,通过编写Selenium脚本,可以实现自动打开12306网站、定位到用户名密码输入框并填充信息、以及点击登录按钮的过程。
自动识别验证码:在遇到验证码时,Selenium可以截图保存验证码图片,然后使用图像识别库(如Tesseract OCR)对图片中的文本内容进行识别,识别后的结果可以被用来填写验证码输入框。
处理交互式验证码:12306有时会弹出交互式验证码要求用户手动点击,对此,Selenium可以监控页面的变化,一旦出现此类验证码,即通过模拟鼠标点击的方式完成验证。
等待页面响应:由于网络延迟或页面加载缓慢,Selenium提供等待机制保证脚本能够正确响应页面状态变化后再执行下一步操作。
异常处理:考虑到网络请求可能失败或脚本执行可能出现错误,使用tryexcept结构来增加脚本的健壮性。
2、利用Requests和OCR库进行服务器交互
发送登录请求:使用Requests库向12306服务器发送POST请求,携带用户名和加密后的密码。
验证码识别与验证:同样可以利用Tesseract OCR进行验证码图片的识别工作,与Selenium方案不同的是,需要先使用Requests获取验证码图片的URL,下载后进行识别。
处理登录结果:分析登录请求的响应,判断是否登录成功,如果不成功,根据错误信息调整登录策略。
3、绕过登录页面的技术探讨
查找破绽和API:部分服务可能存在设计上的缺陷,或者未公开的API接口,可以通过这些方式尝试绕过登录页面,这种方法的可行性和合法性都存疑,不推荐使用。
登录缓存利用:在某些情况下,登录信息可能会被浏览器或服务器缓存,如果能够利用这一点,或许可以在不手动输入用户名和密码的情况下访问一些信息,但这种方式稳定性差,且有安全风险。
4、工具和库的选择
Selenium:一个成熟的浏览器自动化框架,支持多种浏览器和编程语言。
Requests:一个简洁且常用的HTTP库,用于发送网络请求。
Tesseract OCR:一个强大的开源OCR引擎,可以识别多种格式的图片文件并将结果输出为文本。
5、注意事项和潜在问题
法律与规则:自动登录和抢购票可能违反12306的使用规定,存在账号被封禁的风险。
验证码更新:12306会定期更新其验证码机制,这意味着上述方法可能需要针对新的验证码进行调整。
系统兼容性:不同操作系统和环境可能需要额外的配置才能使相关库正常工作。
以下是运用上述方法时需要注意的事项及潜在问题:
法律与规则:自动登录和抢购票可能违反12306的使用规定,存在账号被封禁的风险。
验证码更新:12306会定期更新其验证码机制,这意味着上述方法可能需要针对新的验证码进行调整。
系统兼容性:不同操作系统和环境可能需要额外的配置才能使相关库正常工作。
通过Python实现自动登录12306并自动点击验证码是可行的,但需要结合多种技术,且要面临一定的挑战,考虑到法律风险和系统兼容性问题,使用者应当谨慎选择实施方案,并做好应对措施。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/43871.html