上一篇
c如何做数据库缓存
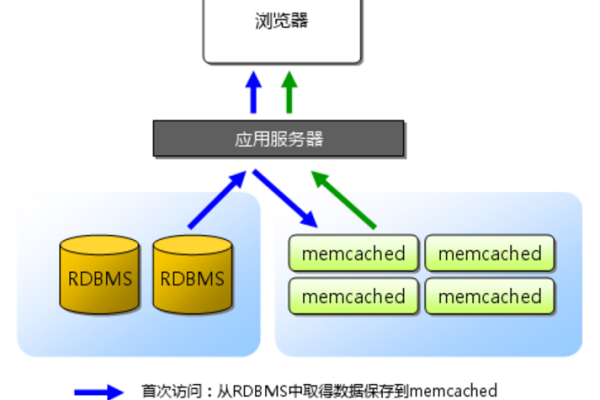
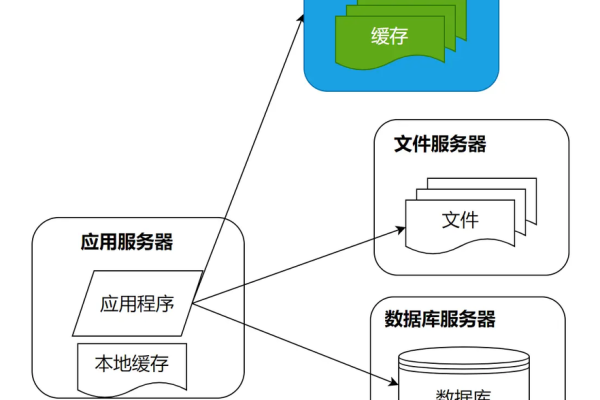
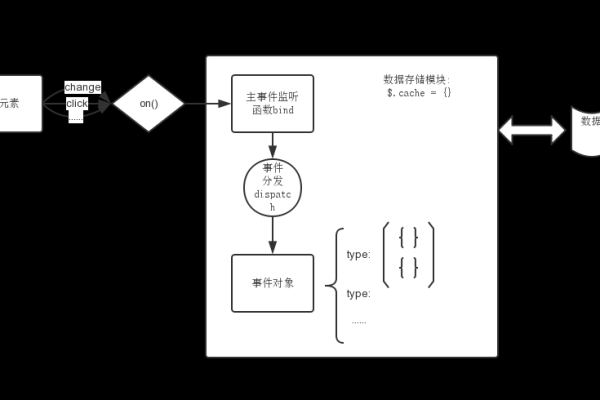
一、缓存的基本概念,,1. **定义**:缓存是一种用于临时存储数据的机制,目的是减少对数据库的直接访问次数,提高数据读取速度和系统性能。,,2. **工作原理**:当应用程序请求数据时,首先检查缓存中是否存在该数据。如果存在,则直接从缓存中读取;如果不存在,则从数据库中读取,并将数据存储在缓存中,以便下次访问时可以直接从缓存中获取。,, 二、常见的缓存技术,,1. **内存缓存**:如Redis和Memcached,将数据存储在内存中,提供快速的数据访问。适用于需要高性能缓存的场景。,,2. **磁盘缓存**:将数据存储在磁盘上,虽然访问速度不如内存缓存,但存储容量较大,适用于需要缓存大量数据的场景。,,3. **应用级缓存**:在应用程序内部实现数据缓存机制,通常使用数据结构(如HashMap、ConcurrentHashMap)来存储缓存数据。适用于单节点应用程序或小规模集群应用。,,4. **文件缓存**:将数据存储在文件系统中,以便快速访问。适用于较大的数据对象或不易频繁变动的数据。,,5. **CDN缓存**:主要用于静态资源的缓存,如图片、CSS、JavaScript等,可以大幅减少数据库的负载,但不适用于动态数据的缓存。,, 三、缓存策略选择,,1. **缓存粒度**:决定缓存数据的细致程度。粒度越细,缓存的命中率越高,但也会占用更多的内存。反之,粒度越粗,内存占用较少,但命中率也会降低。,,2. **缓存失效策略**:设置缓存数据的生命周期,如固定时间过期、LRU(Least Recently Used)等,以确保缓存数据的有效性和一致性。,,3. **缓存一致性管理**:确保缓存中的数据与数据库中的数据一致。常见的方法包括写通过、写回等策略。,, 四、缓存的实现步骤,,1. **确定缓存需求**:评估哪些数据需要被缓存,以及数据的访问频率和更新频率。,,2. **选择缓存技术**:根据需求选择合适的缓存技术,如Redis、Memcached或应用内缓存等。,,3. **实现缓存逻辑**:在应用程序中实现缓存逻辑,包括数据的读取、写入和删除操作。,,4. **监控和优化**:使用缓存框架提供的监控工具或集成第三方监控工具,实时监控缓存的命中率、失效率和性能指标。根据监控数据调整缓存策略和配置,以达到最佳性能。,, 五、缓存的最佳实践,,1. **选择合适的缓存大小**:根据实际需求和资源限制,合理设置缓存大小。,,2. **合理设置缓存失效时间**:根据数据的更新频率和访问频率合理设置缓存失效时间。,,3. **避免缓存雪崩**:通过设置不同的失效时间、增加缓存层级等方式,避免大量缓存同时失效导致数据库负载急剧增加。,,4. **使用分布式缓存**:对于高并发、大规模应用,可以使用分布式缓存来提高缓存的可用性和扩展性。,,5. **考虑缓存预热**:在应用启动或缓存失效时,提前加载部分常用数据到缓存中,以减少首次访问的延迟。
在C语言中实现数据库缓存可以显著提高应用程序的性能,特别是在处理大量数据库查询时,下面是一些步骤和示例代码,展示如何在C语言中实现数据库缓存。

选择缓存策略
你需要确定你的缓存策略,常见的缓存策略包括LRU(最近最少使用)、LFU(最不常用)和FIFO(先进先出),这里我们以LRU为例。
设计数据结构
为了实现LRU缓存,我们需要一个双向链表和一个哈希表,双向链表用于维护缓存的顺序,哈希表用于快速查找缓存项。
include <stdio.h>
include <stdlib.h>
include <string.h>
define CACHE_SIZE 5 // 假设缓存大小为5
typedef struct CacheItem {
char key[256];
char value[256];
struct CacheItem *prev, *next;
} CacheItem;
typedef struct LRUCache {
CacheItem *head, *tail;
CacheItem* hashTable[CACHE_SIZE];
int count;
} LRUCache;
// 初始化LRU缓存
LRUCache* initCache() {
LRUCache *cache = (LRUCache *)malloc(sizeof(LRUCache));
cache->head = cache->tail = NULL;
memset(cache->hashTable, 0, sizeof(cache->hashTable));
cache->count = 0;
return cache;
}
// 哈希函数
unsigned int hashFunction(const char *key) {
unsigned int hash = 0;
while (*key) {
hash = (hash << 5) + *key++;
}
return hash % CACHE_SIZE;
}
// 将节点移动到头部
void moveToHead(LRUCache *cache, CacheItem *item) {
if (cache->head == item) return;
if (item->prev) item->prev->next = item->next;
if (item->next) item->next->prev = item->prev;
if (cache->tail == item) cache->tail = item->prev;
item->next = cache->head;
item->prev = NULL;
if (cache->head) cache->head->prev = item;
cache->head = item;
if (cache->tail == NULL) cache->tail = item;
}
// 获取缓存值
char* getValue(LRUCache *cache, const char *key) {
unsigned int index = hashFunction(key);
CacheItem *item = cache->hashTable[index];
while (item && strcmp(item->key, key)) {
item = item->next;
}
if (!item) return NULL;
moveToHead(cache, item);
return item->value;
}
// 插入新缓存项
void putValue(LRUCache *cache, const char *key, const char *value) {
unsigned int index = hashFunction(key);
CacheItem *item = cache->hashTable[index];
while (item && strcmp(item->key, key)) {
item = item->next;
}
if (item) {
strcpy(item->value, value);
moveToHead(cache, item);
return;
}
if (cache->count >= CACHE_SIZE) {
// 移除尾部节点
CacheItem *oldTail = cache->tail;
if (oldTail->prev) oldTail->prev->next = NULL;
cache->tail = oldTail->prev;
cache->hashTable[hashFunction(oldTail->key)] = oldTail->next;
free(oldTail);
cache->count--;
}
// 添加新节点到头部
CacheItem *newItem = (CacheItem *)malloc(sizeof(CacheItem));
strcpy(newItem->key, key);
strcpy(newItem->value, value);
newItem->prev = NULL;
newItem->next = cache->head;
if (cache->head) cache->head->prev = newItem;
cache->head = newItem;
if (cache->tail == NULL) cache->tail = newItem;
cache->hashTable[index] = newItem;
cache->count++;
}与数据库交互
在实际应用中,你需要将数据库查询结果存储到缓存中,并在需要时从缓存中获取数据,以下是一个简单的示例:
include <mysql/mysql.h>
MYSQL *conn;
MYSQL_RES *res;
MYSQL_ROW row;
// 初始化数据库连接
void initDB() {
conn = mysql_init(NULL);
if (!mysql_real_connect(conn, "host", "user", "password", "database", 0, NULL, 0)) {
fprintf(stderr, "%s
", mysql_error(conn));
exit(1);
}
}
// 执行查询并缓存结果
void queryAndCache(LRUCache *cache, const char *query) {
if (mysql_query(conn, query)) {
fprintf(stderr, "%s
", mysql_error(conn));
return;
}
res = mysql_store_result(conn);
while ((row = mysql_fetch_row(res)) != NULL) {
char key[256], value[256];
sprintf(key, "%s", row[0]); // 假设第一列是键
sprintf(value, "%s", row[1]); // 假设第二列是值
putValue(cache, key, value);
}
mysql_free_result(res);
}
// 从缓存中获取数据
void getFromCache(LRUCache *cache, const char *key) {
char *value = getValue(cache, key);
if (value) {
printf("Cache hit: %s -> %s
", key, value);
} else {
printf("Cache miss: %s
", key);
}
}清理资源
在程序结束时,确保释放所有分配的资源。
void freeCache(LRUCache *cache) {
CacheItem *current = cache->head;
while (current) {
CacheItem *next = current->next;
free(current);
current = next;
}
free(cache);
}FAQs
Q1: 如果缓存满了怎么办?
A1: 当缓存满了时,根据LRU策略,我们会移除最近最少使用的缓存项,然后插入新的缓存项,这通过移动链表节点来实现。
Q2: 如何选择合适的缓存大小?
A2: 缓存大小的选择取决于应用程序的需求和可用内存,可以通过性能测试来确定最佳的缓存大小,如果缓存过小,可能会导致频繁的数据库查询;如果缓存过大,可能会浪费内存资源。
小编有话说
在C语言中实现数据库缓存虽然复杂,但通过合理的数据结构和算法,可以显著提高应用程序的性能,希望本文能帮助你理解如何在C语言中实现简单的LRU缓存机制,并结合数据库操作来提升应用效率,如果你有任何问题或建议,欢迎在评论区留言!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/402635.html