上一篇
如何高效地将CSV文件数据写入数据库?
,,用Python将CSV数据写入数据库:该文介绍通过pandas库读取CSV文件,再利用SQLAlchemy将数据写入MySQL数据库的步骤,包括环境配置、代码实现及注意事项。
在当今数据驱动的时代,CSV(逗号分隔值)文件因其简单性和兼容性,成为了数据交换的常用格式,随着数据量的激增和对数据处理效率的要求提高,将CSV文件中的数据写入数据库变得尤为重要,本文将详细探讨如何高效地将CSV数据写入数据库,包括所需的工具、步骤以及可能遇到的问题和解决方案。

一、所需工具与环境准备
1、编程语言:Python是处理此类任务的理想选择,因其拥有丰富的库支持,如pandas用于数据处理,SQLAlchemy或pymysql等用于数据库操作。
2、数据库系统:MySQL、PostgreSQL、SQLite等都是常见的选择,具体取决于项目需求和规模。
3、开发环境:确保安装了Python及上述提到的相关库。
二、步骤详解
读取CSV文件
使用pandas库可以轻松读取CSV文件:
import pandas as pd 替换为你的CSV文件路径 csv_file_path = 'data.csv' df = pd.read_csv(csv_file_path)
连接数据库
以MySQL为例,使用pymysql库建立连接:
import pymysql
数据库配置信息
config = {
'host': 'localhost',
'port': 3306,
'user': 'your_username',
'password': 'your_password',
'db': 'your_database',
'charset': 'utf8mb4'
}
connection = pymysql.connect(**config)数据预处理(可选)
根据需要对DataFrame进行清洗、转换等操作,以确保数据符合数据库表结构要求。
写入数据库
有多种方法可以将DataFrame写入数据库,这里介绍两种常用方式:
使用to_sql方法:
df.to_sql('your_table_name', con=connection, if_exists='replace', index=False)批量插入:对于大数据集,可以分批次插入以提高性能:
batch_size = 1000
for start in range(0, len(df), batch_size):
end = min(start + batch_size, len(df))
batch_df = df[start:end]
batch_df.to_sql('your_table_name', con=connection, if_exists='append', index=False)关闭连接
操作完成后,记得关闭数据库连接:
connection.close()
三、常见问题与解决方案
Q1: 遇到“Data too long for column”错误怎么办?
A1: 这通常是因为CSV中的某个字段长度超过了数据库表中对应列的限制,检查并调整CSV数据或修改数据库表结构以适应数据。
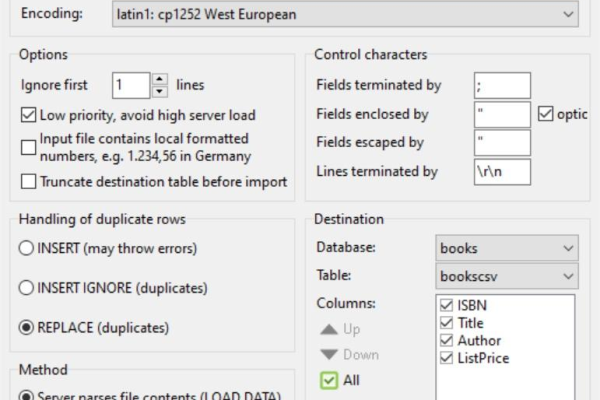
Q2: 如何处理含有特殊字符(如引号、逗号)的CSV数据?
A2: pandas的read_csv函数提供了多种参数来处理这种情况,比如设置quotechar、escapechar等参数,或者在读取后对数据进行进一步清洗。
四、小编有话说
将CSV数据写入数据库虽然看似简单,但实际操作中可能会遇到各种挑战,如数据格式不匹配、性能优化等,通过合理选择工具和方法,以及细心处理每一个步骤,可以有效提高数据处理的效率和准确性,希望本文能为你提供实用的指导,让你的数据迁移之路更加顺畅!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/402545.html