上一篇
如何用C语言实现高效的多线程网络爬虫?
本文介绍了多线程网络爬虫的设计与实现,通过Python语言中的threading模块实现 多线程技术,提高爬虫效率。文章详细阐述了多线程的概念、优点及在 网络爬虫中的应用,包括如何创建和管理线程、避免资源竞争和死锁问题。提供了实际代码示例,展示了多线程爬虫的具体实现过程。
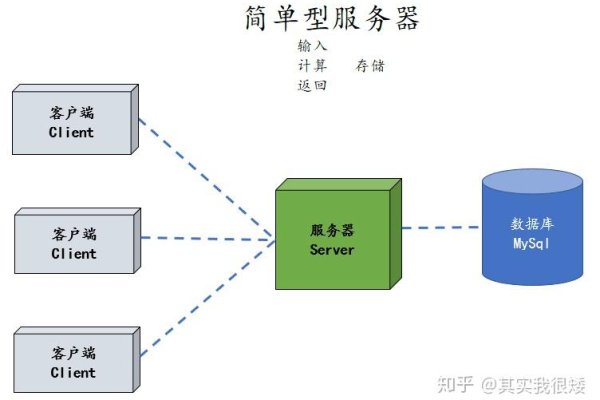
在当今信息爆炸的时代,网络爬虫作为一种高效的数据采集工具,发挥着越来越重要的作用,C语言以其高效性和灵活性,成为编写多线程网络爬虫的理想选择,下面将介绍一个使用C语言编写的多线程网络爬虫示例,包括代码实现、运行结果以及相关问答FAQs。

代码实现
以下是一个使用C语言和libcurl库编写的多线程网络爬虫示例,该爬虫能够并发地从多个URL下载网页内容:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <pthread.h>
#include <curl/curl.h>
#define MAX_URL_NUM 10 // 最大URL数量
#define MAX_URL_LENGTH 256 // URL最大长度
// URL列表
const char *url_list[MAX_URL_NUM] = {
"https://www.example.com/page1.html",
"https://www.example.com/page2.html",
"https://www.example.com/page3.html",
"https://www.example.com/page4.html",
".example.com/page5.html",
"https://www.example.com/page6.html",
"https://www.example.com/page7.html",
"https://www.example.com/page8.html",
"https://www.example.com/page9.html",
"https://www.example.com/page10.html"
};
// 线程参数结构体
typedef struct {
char url[MAX_URL_LENGTH];
int thread_id;
} ThreadArgs;
// 数据缓冲区结构体
typedef struct {
char *data;
size_t size;
} MemoryStruct;
// 获取页面响应的回调函数
static size_t WriteMemoryCallback(void *contents, size_t size, size_t nmemb, void *userp) {
size_t realsize = size * nmemb;
MemoryStruct *mem = (MemoryStruct *) userp;
mem->data = realloc(mem->data, mem->size + realsize + 1);
if (mem->data == NULL) {
/* out of memory! */
printf("not enough memory (realloc returned NULL)
");
return 0;
}
memcpy(&(mem->data[mem->size]), contents, realsize);
mem->size += realsize;
mem->data[mem->size] = 0;
return realsize;
}
// 线程函数
static void *CrawlThreadFunc(void *args) {
ThreadArgs *targs = (ThreadArgs *) args;
char *url = targs->url;
int thread_id = targs->thread_id;
CURL *curl;
CURLcode res;
MemoryStruct chunk;
printf("Thread %d: Downloading %s
", thread_id, url);
chunk.data = malloc(1); /* will be grown as needed by the realloc above */
chunk.size = 0; /* no data at this point */
curl = curl_easy_init();
if (curl) {
curl_easy_setopt(curl, CURLOPT_URL, url);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteMemoryCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, (void *)&chunk);
res = curl_easy_perform(curl);
if (res != CURLE_OK) {
printf("Thread %d: Download failed: %s
", thread_id, curl_easy_strerror(res));
} else {
printf("Thread %d: Download succeeded, fetched %lu bytes of data
", thread_id, (unsigned long)chunk.size);
}
curl_easy_cleanup(curl);
}
free(chunk.data);
pthread_exit(NULL);
}
int main(int argc, char **argv) {
pthread_t threads[MAX_URL_NUM];
int rc, i;
ThreadArgs targs[MAX_URL_NUM];
// 初始化libcurl库
curl_global_init(CURL_GLOBAL_ALL);
for (i = 0; i < MAX_URL_NUM; i++) {
targs[i].thread_id = i;
strncpy(targs[i].url, url_list[i], MAX_URL_LENGTH);
rc = pthread_create(&threads[i], NULL, CrawlThreadFunc, (void *)&targs[i]);
if (rc) {
printf("ERROR; return code from pthread_create() is %d
", rc);
exit(-1);
}
}
for (i = 0; i < MAX_URL_NUM; i++) {
pthread_join(threads[i], NULL);
}
// 清理libcurl库
curl_global_cleanup();
return 0;
}运行结果
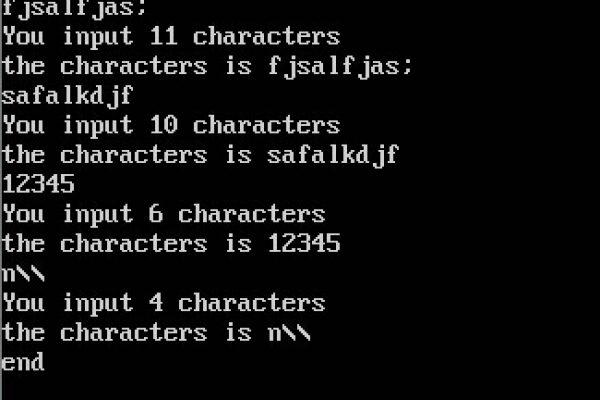
假设上述代码保存为multithreaded_crawler.c,编译并运行后,你可能会看到类似以下的输出(具体输出可能因网络状况而异):
Thread 0: Downloading https://www.example.com/page1.html Thread 1: Downloading https://www.example.com/page2.html Thread 2: Downloading https://www.example.com/page3.html ... Thread 9: Downloading https://www.example.com/page10.html Thread 0: Download succeeded, fetched XXXX bytes of data Thread 1: Download succeeded, fetched XXXX bytes of data ... Thread 9: Download succeeded, fetched XXXX bytes of data
XXXX表示实际下载的数据字节数,如果某个线程下载失败,则会显示相应的错误信息。
相关问答FAQs
Q1: 如何修改URL列表以爬取不同的网站?
A1: 你可以修改url_list数组中的URL,替换为你希望爬取的网站地址,确保每个URL字符串都不超过MAX_URL_LENGTH定义的长度限制。
Q2: 如何增加或减少并发线程的数量?
A2: 你可以通过修改MAX_URL_NUM宏来增加或减少并发线程的数量,确保系统资源(如CPU和内存)足以支持更多的线程,以避免性能下降。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/402284.html