上一篇
如何选择最适合的存储结构以优化数据管理?
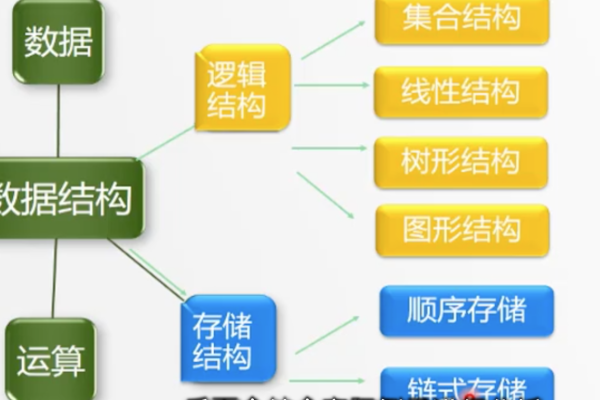
### ,,存储结构是数据组织和管理的关键,包括顺序、链接、索引和散列存储。顺序存储便于随机访问但插入删除效率低;链接存储通过指针连接数据,适合动态操作但访问速度慢;索引存储利用索引表加速查找;散列存储通过哈希函数实现快速定位,但需处理哈希冲突。选择合适 存储结构需考虑数据特性、操作需求及应用场景。
在计算机科学和编程领域,存储结构的选择对于程序的性能、可维护性以及扩展性至关重要,不同的存储结构适用于不同的应用场景,理解各种存储结构的特点及其适用情况是开发者必备的技能之一,下面将详细介绍几种常见的存储结构及其选择依据。

一、数组(Array)
特点:
连续内存分配:数组在内存中是连续存储的,这使得通过索引访问元素非常快速。
固定大小:一旦定义,数组的大小通常不能改变。
类型统一:数组中的所有元素必须是相同的数据类型。
适用场景:
需要频繁随机访问元素的场景。
元素数量已知且不会变化的情况。
对性能要求极高的场合,如游戏开发中的像素处理。
二、链表(Linked List)
特点:
非连续内存分配:每个节点包含数据及指向下一个节点的指针,内存可以不连续。
动态大小:易于插入和删除操作,无需移动其他元素。
灵活性高:可以方便地实现双向链表或循环链表等变体。
适用场景:
需要频繁插入和删除元素的场景。
元素数量不确定或经常变化的情况。
实现某些特定算法(如多项式加法)时较为方便。
三、栈(Stack)与队列(Queue)
栈:
后进先出(LIFO):最后加入的元素最先被移除。
应用场景:函数调用栈、表达式求值、深度优先搜索等。
队列:
先进先出(FIFO):最早加入的元素最先被移除。
应用场景:任务调度、广度优先搜索、缓冲区管理等。
四、哈希表(Hash Table)
特点:
快速查找:通过哈希函数计算键值对应的索引,实现平均时间复杂度为O(1)的查找、插入和删除操作。
处理冲突:需要解决哈希碰撞问题,常用方法包括开放寻址法和链地址法。
适用场景:
需要快速查找、插入和删除大量数据的场景。
实现字典、集合等数据结构时非常有效。
五、树结构(Tree)
二叉树:
节点最多有两个子节点。
应用场景:二叉搜索树用于排序和查找;平衡二叉树(如AVL树、红黑树)保持树的高度平衡,提高操作效率。
多路搜索树:
节点可以有多个子节点,如B树、B+树广泛应用于数据库和文件系统的索引结构中。
六、图结构(Graph)
特点:
由节点和边组成,用于表示复杂的关系网络。
应用场景:社交网络分析、路由规划、推荐系统等。
七、散列表(Sparse Table)与倒排索引(Inverted Index)
散列表:
高效处理稀疏矩阵,常用于数值计算和科学计算领域。
倒排索引:
文本搜索引擎的核心组件,快速定位包含特定关键词的文档。
八、选择存储结构的考虑因素
| 考虑因素 | 说明 |
| 数据量 | 小数据集可能更适合简单的结构,大数据集则需考虑更高效的结构。 |
| 操作类型 | 频繁插入和删除适合链表,频繁查找适合哈希表或树结构。 |
| 内存使用 | 数组和哈希表通常需要较多的连续内存,而链表则相对灵活。 |
| 性能要求 | 对性能敏感的应用应选择能提供最佳时间复杂度的结构。 |
| 易用性和可维护性 | 简单直观的结构更容易理解和实现,但可能牺牲一些性能。 |
FAQs
Q1: 为什么在很多情况下推荐使用链表而不是数组?
A1: 链表的主要优势在于其动态大小和高效的插入/删除操作,与数组相比,链表不需要预先分配固定大小的内存块,因此在处理未知数量或频繁变动的数据时更加灵活,链表的插入和删除操作通常只需要修改几个指针,而不需要像数组那样移动大量元素,从而提高了效率。
Q2: 哈希表如何解决哈希碰撞问题?
A2: 哈希碰撞是指两个不同的键通过哈希函数映射到同一个索引上的现象,解决哈希碰撞的方法主要有两种:开放寻址法和链地址法,开放寻址法尝试在哈希表中找到另一个空闲位置来存储发生碰撞的元素;而链地址法则在每个索引位置维护一个链表,将所有映射到该索引的元素存储在这个链表中,这两种方法各有优缺点,选择哪种方法取决于具体应用场景和性能要求。
小编有话说
选择合适的存储结构是软件开发中的一个重要决策点,它不仅影响到程序的性能和效率,还关系到代码的可读性和可维护性,作为开发者,我们应该根据具体的应用需求和场景特点来权衡各种存储结构的优缺点,做出明智的选择,也要不断学习和探索新的存储技术和方法,以适应不断变化的技术环境和业务需求。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/401525.html