上一篇
CPU深度学习加速器,如何提升AI计算效率?
### ,,CPU深度学习加速器是专为加速 深度学习计算而设计的硬件设备,相比传统CPU和GPU,具有更高的计算效率、更低的能耗和更小的尺寸。它通过优化硬件结构和算法,大幅提高模型训练和推理的速度与准确性,广泛应用于语音识别、图像处理等领域,推动了深度学习技术的发展。
一、算法顶层
1、大规模分布式机器学习:随着模型和数据量的增大,需要多机协同训练,并行方式有数据并行(每台机器都有模型副本,处理不同数据部分)和模型并行(模型各部分分散在不同机器间,更新参数时需层间通信),实际中常将两者结合,调度方式分为集中式调度(如Parameter Server架构)和去中心化调度(如Ring Allreduce),Parameter Server作为集中式架构,负责存放全局参数,worker进行训练,可通过参数平均或基于梯度的方式进行同步更新,也有异步更新方式,Ring Allreduce则将参数通信分散到各个GPU,能实现计算性能随GPU并行卡数增加而线性增长。

2、优化算法:各种优化算法如SGD、Adagrad、Adadelta、RMSprop、Momentum、Adam、Adamax、Nadam等,其目标是使梯度下降搜索更趋近全局最优,加速收敛速度,从而加快训练进度,在分布式机器学习系统中,这些优化算法也需实现相应的分布式版本。
3、轻量级网络设计:由于早期经典模型参数存在冗余,难以部署在存储有限的边缘设备,因此出现轻量级网络设计,如减小卷积核大小、采用1×1卷积等,以减少参数和乘法操作,加快速度。
4、神经网络架构搜索:通过自动化的网络搜索机制,寻找更优的神经网络架构,进一步提高模型性能和训练效率。
5、量化与剪枝:对网络参数进行量化和剪枝,减少模型的存储和计算需求,提高运行速度,同时在一定程度上保持模型的性能。
6、卷积运算的优化:针对深度学习中计算量较大的卷积操作进行优化,如采用快速傅里叶变换(FFT)等方法加速卷积计算。
二、深度学习编译器
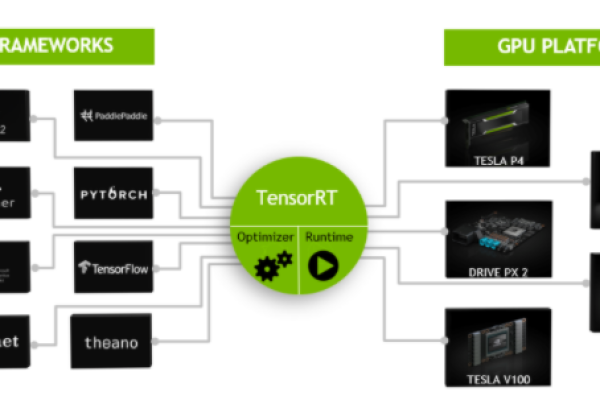
1、TVM:是一个用于深度学习模型编译的开源框架,可将高层的神经网络描述转换为底层的硬件可执行代码,支持多种硬件平台,包括CPU、GPU、FPGA等,能够根据不同的硬件特性进行优化,提高模型的运行效率。
2、Pytorch Glow:是Facebook推出的用于PyTorch的编译器,旨在提高PyTorch模型的性能和效率,通过将模型中的计算图进行优化和转换,生成更高效的中间表示,以便在不同的硬件上更好地运行。
3、Tensorflow XLA:是Google为TensorFlow开发的编译器,能够对TensorFlow计算图进行优化和编译,生成高效的机器码,提升模型的训练和推理速度,支持多种硬件平台,并且可以自动进行一些常见的优化操作,如向量化、并行化等。
三、体系结构与硬件设计
1、CPU和GPU平台:CPU具有通用性强、灵活性高的特点,适用于各种类型的计算任务,但在深度学习计算中,其并行计算能力相对较弱,GPU则具有强大的并行计算能力,能够高效地处理大规模的矩阵运算和卷积操作,是目前深度学习训练中最常用的硬件加速器之一,不过,GPU的功耗较高,且对于一些小规模的计算任务可能存在资源浪费的情况。
2、Domain-Specific硬件设计:针对特定的深度学习任务和应用需求,设计专门的硬件架构,如TPU(Tensor Processing Unit)、NPU(Neural Network Processing Unit)等,这些专用硬件通常针对深度学习中的某些关键计算操作进行了高度优化,能够提供更高的计算效率和更低的功耗,但缺乏通用性,适用范围相对较窄。
3、加速器设计利用的特性:充分利用硬件的稀疏性、低精度计算、压缩技术等特性来提高加速器的性能和效率,利用稀疏矩阵的特性可以减少内存访问和计算量;采用低精度计算可以在不显著影响模型性能的前提下,降低存储需求和计算成本;通过数据压缩技术可以减少数据传输量,提高带宽利用率。
4、经典的加速器设计案例:如DianNao、PuDiannao、Eyeriss等,DianNao是一款基于FPGA的深度学习加速器,采用了独特的数据流和存储策略,提高了计算效率;PuDiannao是一种可扩展的高性能深度学习加速器架构,通过优化内存子系统和计算单元的组织方式,实现了高效的计算性能;Eyeriss则是一种面向卷积神经网络的加速器架构,通过复用计算资源和优化数据路径,提高了卷积计算的效率。
四、相关问答
1、CPU深度学习加速器与传统的CPU相比有哪些优势?
传统的CPU在处理深度学习任务时,虽然具有一定的通用性和灵活性,但其并行计算能力相对较弱,对于大规模的矩阵运算和卷积操作等计算密集型任务,效率较低,而CPU深度学习加速器则通过专门针对深度学习计算特点进行优化,如采用SIMD指令集、多核并行计算、优化内存访问等方式,能够显著提高深度学习任务的计算效率,一些加速器还采用了特殊的硬件架构和数据流设计,进一步减少了计算延迟和数据传输开销,从而在整体性能上优于传统CPU。
2、如何选择适合自己需求的CPU深度学习加速器?
首先需要考虑应用的具体需求,如模型类型、数据规模、计算精度要求等,如果处理的是大规模的图像识别或自然语言处理任务,且对计算速度要求较高,那么可以选择具有强大并行计算能力和大内存带宽的加速器,如基于GPU或TPU的加速器,如果是在一些资源受限的场景下,如边缘设备或移动设备,对功耗和成本较为敏感,那么可以考虑采用轻量级的加速器解决方案,如基于FPGA或ASIC的定制加速器,或者选择一些优化较好的开源加速器框架,如TVM等,还需要考虑加速器与现有硬件平台的兼容性、开发难度以及生态系统的支持等因素。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/401369.html