
上一篇
如何实现数据库中的唯一计数,不计算重复项的方法探讨
### ,,本文介绍了在数据库中统计不重复数据的方法,包括使用SQL的DISTINCT关键字、GROUP BY关键字以及COUNT函数。通过这些方法,可以有效地实现对不重复数据的统计,满足各种数据统计需求。
在数据库管理中,COUNT 是一个常用的聚合函数,用于统计满足特定条件的行数,在某些情况下,我们可能不希望计算重复的数据,当我们有一个包含重复记录的表时,如果我们直接使用COUNT(*),它会计算所有行,包括重复的行,这时,我们需要一种方法来避免重复计数。

使用 DISTINCT 关键字
在 SQL 中,我们可以使用DISTINCT 关键字来确保只计算唯一的行。
SELECT COUNT(DISTINCT column_name) FROM table_name;
这条语句会返回column_name 列中不同值的数量,如果你想要统计整行的唯一性,可以这样做:
SELECT COUNT(*) FROM (SELECT DISTINCT * FROM table_name) AS unique_rows;
这会先创建一个只包含唯一行的临时表,然后对这个临时表进行计数。
示例表格
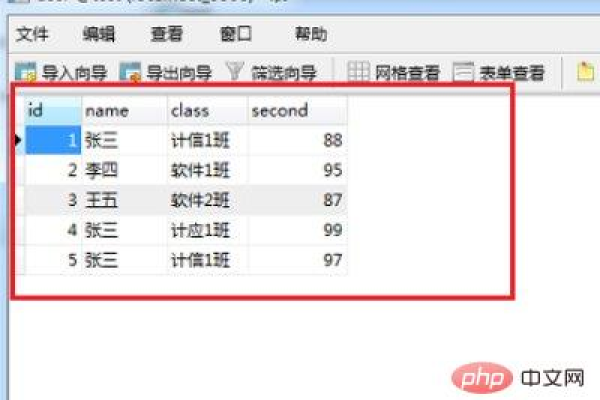
假设我们有一个名为employees 的表,结构如下:
| id | name | department |
| 1 | Alice | HR |
| 2 | Bob | IT |
| 3 | Alice | HR |
| 4 | Carol | IT |
| 5 | Bob | IT |
如果我们想统计不同员工的数量(即不计算重复的员工),我们可以使用以下查询:
SELECT COUNT(DISTINCT name) FROM employees;
这将返回 3,因为有三位不同的员工(Alice, Bob, Carol)。
FAQs
Q1: 如果我想统计多个列的组合唯一性,应该怎么办?
A1: 你可以使用DISTINCT 关键字后跟多个列名,用逗号分隔,如果你想统计每个部门中不同员工的数量,你可以这样做:
SELECT department, COUNT(DISTINCT name) FROM employees GROUP BY department;
这将返回每个部门中不同员工的数量。
Q2: 使用DISTINCT 是否会影响查询性能?
A2: 是的,使用DISTINCT 可能会影响查询性能,因为它需要额外的处理来识别和消除重复的行,具体影响取决于数据量、索引的存在与否以及数据库管理系统的优化策略,在大型数据集上使用时,最好先在测试环境中评估其性能影响。
小编有话说
在使用COUNT 函数时,记得考虑是否需要排除重复的数据,通过合理使用DISTINCT 关键字,我们可以更准确地获取所需的统计信息,也要注意这种操作可能会对查询性能产生的影响,特别是在处理大数据集时,希望这篇文章能帮助你更好地理解如何在 SQL 中进行非重复计数。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/400510.html
相关文章
-
python查找列表重复项,如何筛选某一列的重复项(python查找列表中的重复值)
-
什么是数据库中的唯一索引,它如何确保数据的唯一性?
-
什么是数据库中的唯一索引?它如何确保数据的唯一性?
-
如何在MySQL数据库中创建一个有效的唯一索引语句来确保数据列的唯一性?
-
MenuItem,探索菜单项的创新设计与实现,以疑问句的形式呈现,旨在引发读者对菜单项设计的兴趣和思考。同时,它暗示了文章可能会探讨菜单项的设计原则、创新方法以及实现细节等方面的内容。
-
如何在MySQL数据库中创建和利用唯一索引来保证数据的唯一性?
-

如何在MySQL数据库中创建唯一索引以确保数据的唯一性?
-
如何在MySQL数据库中实现数据的唯一性?
-
sql如何计算重复出现的次数








