
上一篇
如何用C语言编写高效的网络爬虫程序?
编写网络爬虫需要使用编程语言如Python,并利用相关库如BeautifulSoup和requests来抓取网页数据。
编写网络爬虫是一个涉及多个技术领域的复杂任务,包括HTTP协议、HTML解析、数据提取和存储等,在C语言中编写网络爬虫需要对底层网络编程有一定的了解,下面将详细介绍如何用C语言编写一个简单的网络爬虫。

一、环境准备
在开始编写网络爬虫之前,需要确保开发环境中安装了必要的工具和库:
编译器:GCC或其他支持C99标准的编译器。
网络库:libcurl用于处理HTTP请求。
HTML解析库:libxml2用于解析HTML文档。
正则表达式库:如果需要更复杂的文本处理,可以使用PCRE库。
二、基本步骤
1、发送HTTP请求:使用libcurl库向目标网站发送GET请求,获取网页内容。
2、解析HTML:利用libxml2库解析返回的HTML文档,提取所需的数据。
3、数据处理:对提取的数据进行清洗和格式化。
4、存储数据:将处理后的数据保存到本地文件或数据库中。
5、错误处理:添加异常处理机制,确保程序在遇到错误时能够优雅地退出。
6、遵守robots.txt:在爬取网站前,检查网站的robots.txt文件,尊重网站的爬取规则。
7、多线程/异步处理:为了提高效率,可以采用多线程或异步IO技术来并行处理多个请求。
三、示例代码
以下是一个简单的C语言网络爬虫示例,该示例使用libcurl发送HTTP请求,并使用libxml2解析HTML文档,提取页面中的链接。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <curl/curl.h>
#include <libxml/HTMLparser.h>
// 回调函数,用于接收libcurl传输的数据
size_t write_data(void *ptr, size_t size, size_t nmemb, void *stream) {
size_t real_size = size * nmemb;
((char *)stream)[real_size] = ' 本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/399502.html
相关文章
-
学习如何使用C语言编写高效的HTTP服务器 (c语言编写http服务器)
-
如何利用Java编写高效的网络爬虫?探索源码实例!
-
如何用C语言编写高效的网络检测代码?
-

探索网络爬虫,如何编写有效的c语言爬虫源码?
-
如何用C语言编写高效的数据结构代码?
-
mysql数据库代码_Mysql数据库这篇文章可能涉及MySQL数据库的编程、管理或优化等方面的内容。根据这些信息,我们可以为文章生成一个原创的疑问句标题,例如,,如何编写高效的MySQL数据库代码以提升性能?,不仅提出了一个问题,而且暗示了文章内容可能包含关于编写高效MySQL代码和提升数据库性能的技巧与建议。
-
c语言常见的编译错误,c语言编译错误怎么解决(c语言常见的编译错误,c语言编译错误怎么解决)
-
如何用C语言编写程序?
-
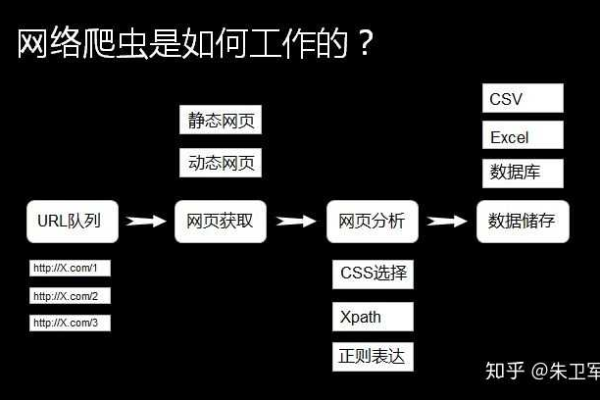
如何运行php爬虫程序








