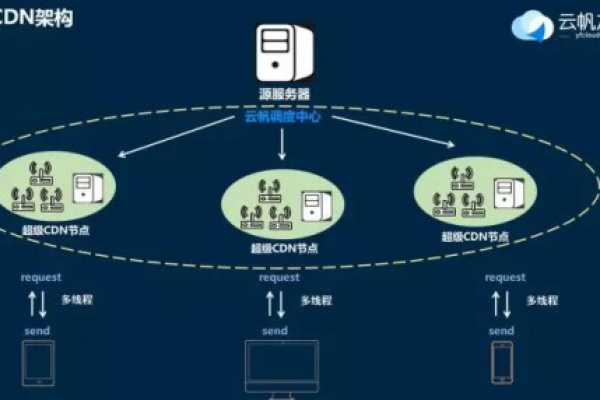
什么是边缘节点CDN?它如何优化网络性能?

边缘节点CDN(内容分发网络)是一种通过将内容缓存到靠近用户的边缘节点,从而加速互联网内容传输的网络架构,它由全球分布的多个服务器组成,这些服务器被称为边缘节点,CDN的主要目标是提供快速、可扩展和可靠的内容传输,减少延迟和带宽消耗。
以下是对边缘节点CDN的详细解释:
1、工作原理
请求路由:当用户访问启用了CDN的站点时,请求首先被发送到离用户最近的CDN边缘节点,而不是直接访问源站,CDN使用智能DNS解析或Anycast路由技术,根据用户的IP地址或地理位置选择一个最近的边缘节点来响应请求,从而减少传输延迟。
内容缓存与更新:CDN的边缘节点会缓存静态内容,如图片、视频、样式表(CSS)、JavaScript文件和网页HTML等,当同一内容被多次请求时,CDN边缘节点会直接响应,避免重复向源服务器请求,减少源服务器负担并加速响应,CDN还会根据缓存策略(如TTL—缓存有效时间)来决定何时从源站刷新缓存。
优化和压缩:除了缓存静态内容外,CDN还可以对传输内容进行优化和压缩,以提高性能,通过gzip或brotli等技术压缩传输的内容,减少数据传输量;自动调整和压缩图像(如WebP格式),根据设备和网络条件提供合适的图像质量,进一步提升加载速度。
高可用性和容错:通过将内容分布到多个地理位置,CDN可以确保即使某个服务器或数据中心发生故障,其他边缘节点仍能继续提供服务,保证高可用性和冗余,CDN采用智能路由和负载均衡技术,将流量分配到最健康、最负载最少的边缘节点。
2、优势
传输:由于CDN将内容缓存到离用户更近的位置,可以减少网络延迟,提高页面加载速度,改善用户体验。
节约带宽成本:CDN通过将内容存储在节点中,减少了从源服务器到用户的数据传输量,从而降低了带宽消耗和网络流量的成本。
提供高可用性和容错能力:即使某个节点发生故障,仍然可以从其他节点获取内容,提供高可用性和容错能力。
缓解源服务器的负载压力:由于CDN可以缓存和提供静态资源,源服务器可以集中精力处理动态内容和数据,从而减轻了服务器的负载压力。
3、应用场景
网站加速:通过将网站的静态资源(如图片、视频、CSS、JavaScript等)缓存到CDN边缘节点,可以显著提高网站的加载速度。
视频流媒体:CDN可以加速视频内容的传输,减少缓冲时间,提高视频播放的流畅度。
在线游戏:在在线游戏场景中,CDN可以确保游戏数据在各个边缘节点之间的快速同步,减少游戏延迟,提高游戏的流畅度和用户体验。
电子商务:CDN可以确保商品信息、交易数据等在各个边缘节点之间的快速同步,减少页面加载时间,提高用户的购物体验。
4、实时同步机制
内容推送:CDN可以通过内容推送的方式,将最新的内容主动推送到边缘节点,从而保证用户在不同地理位置都能迅速访问到最新的内容,这种方式不仅提高了内容的传输速度,还能有效减少中心服务器的负载。
缓存刷新:CDN可以通过定期或按需刷新缓存,确保边缘节点上的内容始终是最新的,定时刷新适用于内容更新频率较低的场景,而按需刷新则适用于高实时性要求的应用场景。
智能调度:CDN可以根据实时网络状况、服务器负载、用户地理位置等因素,动态地调整内容推送和缓存刷新策略,确保内容能够快速、准确地同步到边缘节点。
边缘计算:在边缘节点部署计算资源和应用程序,CDN可以在边缘节点上进行数据处理和内容生成,从而减少对中心服务器的依赖,提升系统的实时性和响应速度。
5、挑战与解决方案
数据一致性:由于边缘节点的分布式特性,数据在不同节点之间可能出现不一致的情况,为了解决这一问题,可以采用分布式数据库和分布式缓存技术,通过数据复制和一致性协议,确保数据在各个节点之间的一致性。
网络延迟:网络延迟是影响CDN实时同步效率的一个重要因素,为了解决这一问题,可以采用多路径传输和流量优化技术,通过选择最优的传输路径和优化数据传输过程,减少网络延迟,提高数据传输效率。
系统可靠性:系统可靠性是保障CDN实时同步正常运行的关键,为了解决这一问题,可以采用分布式架构和容错机制,通过多节点冗余和故障恢复技术,确保系统在任何情况下都能够稳定运行。
6、未来展望
随着互联网技术的发展,CDN实时同步的应用前景将更加广阔,随着5G、物联网、人工智能等技术的普及,CDN实时同步将进一步提升系统的实时性和智能化水平,满足更多高实时性、高可靠性的应用需求。
相关问答FAQs
Q1: CDN如何解析到离用户最近的边缘节点?
A1: 当用户发起一个访问请求时,DNS(Domain Name System)服务器会介入,传统的DNS服务器只负责将域名解析为IP地址,而CDN的DNS服务器则具备智能解析的功能,当用户请求某个域名时,CDN的DNS服务器会根据用户所在的地理位置、网络状况等因素,选择一个最佳的CDN节点(即离用户最近的边缘节点)来返回给用户,这个选择最佳CDN节点的过程称为“路由选择”,CDN服务商通常会部署大量的边缘节点在全球各地,这些节点通过高速网络连接形成一张庞大的网络,当用户请求到达CDN的DNS服务器时,服务器会根据预先配置的策略和实时网络状况,选择一个最合适的节点来为用户提供服务。
Q2: CDN实时同步到边缘节点有哪些方式?
A2: CDN实时同步到边缘节点的方式主要包括内容推送、缓存刷新、智能调度以及边缘计算,内容推送是一种主动的内容同步方式,能够在内容源发生变化时,立即将更新后的内容推送至各个边缘节点,缓存刷新是另一种重要方式,通过定期或按需刷新缓存,确保边缘节点上的内容始终是最新的,智能调度系统可以根据实时网络状况、服务器负载、用户地理位置等因素,动态地调整内容推送和缓存刷新策略,边缘计算则是在边缘节点部署计算资源和应用程序,进行数据处理和内容生成,从而减少对中心服务器的依赖,提升系统的实时性和响应速度。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/3995.html