
上一篇
如何使用C语言进行数据库查询?
当然,请提供您需要查询的具体内容或条件,以便我为您生成相应的数据库查询语句。
在数据库管理中,编写有效的查询语句是至关重要的,无论是进行数据检索、更新还是删除操作,正确使用SQL查询语句可以大大提高数据处理的效率和准确性,下面将详细介绍几种常见的SQL查询语句及其用法,并提供一些实用的示例。

SELECT 语句
基本语法:
SELECT column1, column2, ... FROM table_name;
功能: 从指定的表中选择一列或多列数据。
示例:
假设有一个名为employees的表,包含以下列:id,name,position,salary,要查询所有员工的名字和职位,可以使用以下SQL语句:
SELECT name, position FROM employees;
WHERE 子句
基本语法:
SELECT column1, column2, ... FROM table_name WHERE condition;
功能: 过滤记录,只返回满足特定条件的行。
示例:
要从employees表中查找薪资大于5000的员工,可以使用以下SQL语句:
SELECT * FROM employees WHERE salary > 5000;
ORDER BY 子句
基本语法:
SELECT column1, column2, ... FROM table_name ORDER BY column1 [ASC|DESC], column2 [ASC|DESC], ...;
功能: 对结果集进行排序,默认为升序(ASC),也可以指定为降序(DESC)。
示例:
要按照薪资从高到低的顺序列出所有员工的信息,可以使用以下SQL语句:
SELECT * FROM employees ORDER BY salary DESC;
GROUP BY 子句
基本语法:
SELECT column1, aggregate_function(column2) FROM table_name WHERE condition GROUP BY column1;
功能: 根据一个或多个列对结果集进行分组,并应用聚合函数(如COUNT(), SUM(), AVG()等)。
示例:
要统计每个部门的平均薪资,可以使用以下SQL语句:
SELECT department, AVG(salary) FROM employees GROUP BY department;
HAVING 子句
基本语法:
SELECT column1, aggregate_function(column2) FROM table_name WHERE condition GROUP BY column1 HAVING aggregate_condition;
功能: 过滤分组后的结果集,只保留满足特定条件的组。
示例:
要找出平均薪资超过6000的部门,可以使用以下SQL语句:
SELECT department, AVG(salary) FROM employees GROUP BY department HAVING AVG(salary) > 6000;
JOIN 操作
基本语法:
SELECT columns FROM table1 JOIN table2 ON table1.common_column = table2.common_column;
功能: 结合两个或多个表的数据,基于它们之间的关联键。
示例:
假设有两个表employees和departments,其中employees表有一个外键department_id指向departments表的主键id,要获取每个员工的姓名及其所在部门的名称,可以使用以下SQL语句:
SELECT e.name, d.department_name FROM employees e JOIN departments d ON e.department_id = d.id;
UNION 操作符
基本语法:
SELECT column1, column2, ... FROM table1 UNION SELECT column1, column2, ... FROM table2;
功能: 合并两个或多个SELECT语句的结果集,并去除重复的行。
示例:
要从两个不同的表中获取所有唯一的员工ID,可以使用以下SQL语句:
SELECT id FROM employees UNION SELECT employee_id FROM other_table;
子查询(Subquery)
基本语法:
SELECT column1, column2, ... FROM table_name WHERE column_name = (SELECT column_name FROM another_table WHERE condition);
功能: 在一个查询内部嵌套另一个查询,用于更复杂的数据筛选。
示例:
要查找薪资高于公司平均水平的员工,可以使用以下SQL语句:
SELECT * FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
更新数据(UPDATE)
基本语法:
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;
功能: 修改表中已存在的记录。
示例:
要将employees表中ID为101的员工的工资提升到7000元,可以使用以下SQL语句:
UPDATE employees SET salary = 7000 WHERE id = 101;
删除数据(DELETE)
基本语法:
DELETE FROM table_name WHERE condition;
功能: 从表中移除指定的记录。
示例:
要删除employees表中所有薪资低于3000元的员工记录,可以使用以下SQL语句:
DELETE FROM employees WHERE salary < 3000;
介绍了几种常用的SQL查询语句及其用法,掌握这些基本的操作可以帮助你更有效地管理和分析数据库中的数据,接下来是两个常见问题及其解答。
FAQs:
Q1: 如何在SQL中实现多表连接?
A1: 在SQL中,可以使用JOIN操作来实现多表连接,根据需要选择不同类型的JOIN,如INNER JOIN(内连接)、LEFT JOIN(左连接)、RIGHT JOIN(右连接)和FULL OUTER JOIN(全外连接),要结合两个表的数据,可以使用如下语法:
SELECT columns FROM table1 JOIN table2 ON table1.common_column = table2.common_column;
具体使用哪种类型的JOIN取决于你想要获取的结果集类型,如果只需要两个表中匹配的行,则使用INNER JOIN;如果希望即使没有匹配项也能保留左侧表中的所有记录,则使用LEFT JOIN;同理,RIGHT JOIN保留右侧表的所有记录;FULL OUTER JOIN则保留两侧表中的所有记录。
Q2: 如何优化SQL查询以提高性能?
A2: 优化SQL查询可以通过多种方式实现,包括但不限于以下几点:
确保索引的存在:为经常用于搜索条件(WHERE子句中的列)和排序(ORDER BY子句中的列)的列创建索引。
避免全表扫描:尽可能使用索引来避免对整个表进行扫描,特别是在大数据集上。
简化查询逻辑:减少不必要的复杂性,比如避免过多的嵌套查询和复杂的表达式计算。
使用适当的数据类型:选择合适的数据类型可以减少存储空间并提高处理速度。
限制返回的数据量:仅选择所需的列而不是使用通配符(*),并且尽量限制返回的行数。
利用缓存机制:对于频繁执行但结果相对稳定的查询,可以考虑将其结果缓存起来,以减少数据库的负载。
通过上述方法,你可以显著提高SQL查询的性能,不过,具体的优化策略还需要根据实际情况进行调整。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/396598.html
相关文章
-
如何使用ASP进行数据库查询?
-

如何使用Builderc进行数据库查询?
-
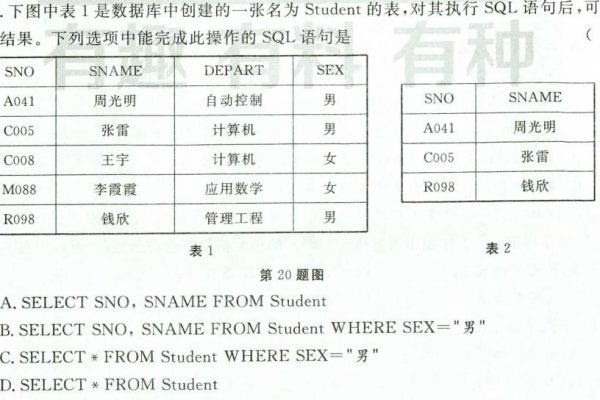
rowcount 一词通常与数据库查询或表格数据行数统计相关。根据这一概念,可以创造一个疑问句标题,例如,,如何准确获取数据库中的 rowcount 值?,提出了一个关于如何正确统计数据库表中的行数的问题,这在数据处理和分析中是一个实用且常见的问题。
-
如何使用易语言进行数据库操作?
-
GaussDB中的通配符有哪些?如何正确使用它们进行数据库查询?
-
如何高效利用织梦万能标签{dede:sql}进行数据库查询?
-
如何在不同服务器之间进行数据库查询?
-

以下几个疑问句标题可供选择,,MySQL 数据库如何进行迁移?数据库迁移服务该怎样使用?,MySQL 数据库的迁移该怎么做?如何使用数据库迁移服务?,怎么对 MySQL 数据库进行迁移?数据库迁移服务应如何使用?
-
如何有效使用易语言进行数据库操作?








