安卓和大数据开发

安卓开发聚焦移动应用,基于Java/Kotlin;大数据开发处理海量数据,依托Hadoop/Spark,两者在数据采集与分析层有技术交集,但前者侧重终端交互,后者专注分布式计算与存储
安卓开发核心要点
技术架构
- 系统层级:Linux内核 + 硬件抽象层(HAL) + 安卓运行时(ART) + 框架层(SDK)
- 四大组件:Activity(界面)、Service(服务)、BroadcastReceiver(广播)、ContentProvider(数据共享)
- 通信机制:Intent机制、Binder机制、Handler/Looper消息循环
开发工具链
| 工具类别 | 代表工具 | 功能说明 |
|---|---|---|
| 集成开发环境 | Android Studio | 代码编写、调试、模拟器管理 |
| 版本控制 | Git | 代码版本管理 |
| 依赖管理 | Gradle | 构建脚本、依赖解析 |
| 性能分析 | Profiler(CPU/Memory) | 实时监控应用性能指标 |
关键特性实现
- UI开发:Material Design组件库、ConstraintLayout布局、RecyclerView列表优化
- 数据存储:SQLite数据库、Room持久化库、SharedPreferences轻量存储
- 网络通信:Retrofit+OkHttp组合、WebSocket长连接、WorkManager离线任务
- 安全机制:权限管理系统、ProGuard代码混淆、SSL/TLS加密传输
大数据开发核心要点
技术生态体系
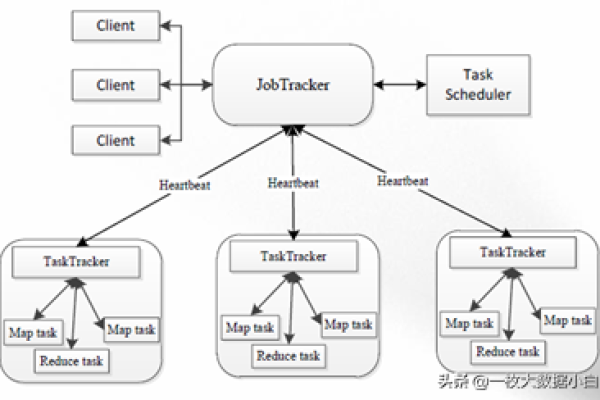
- 数据存储层:HDFS(分布式文件系统)、HBase(NoSQL数据库)、Kafka(消息队列)
- 计算引擎:MapReduce(批处理)、Spark(内存计算)、Flink(流处理)
- 资源管理:YARN(集群资源调度)、Kubernetes(容器编排)
- 数据分析:Pig/Hive(SQL-on-Hadoop)、Spark SQL、Elasticsearch(搜索分析)
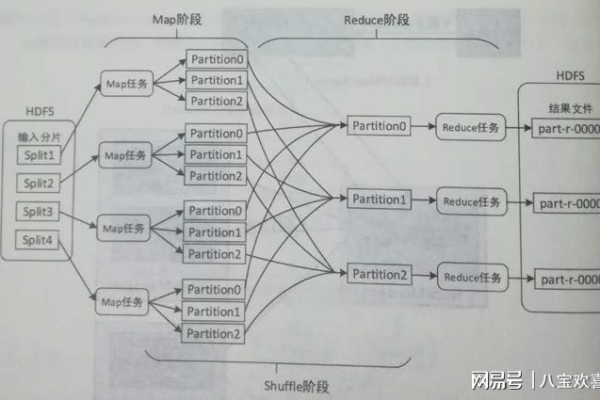
处理流程
graph TD
A[数据采集] --> B[数据传输] --> C{存储方式}
C -->|实时流| D[Kafka]
C -->|批量处理| E[HDFS]
D --> F[Flink Streaming]
E --> G[Spark批处理]
F & G --> H[数据可视化]典型应用场景
- 用户行为分析:日志采集→Flume传输→Kafka缓冲→Spark计算→BI可视化
- 实时推荐系统:Kafka消费→Flink流处理→特征工程→在线学习模型
- 数据仓库建设:ETL工具(如Apache NiFi)→Hive数仓→OLAP分析
安卓与大数据融合场景
数据采集终端
- 设备数据上报:通过HTTP/MQTT协议将传感器数据发送至Kafka集群
- 日志收集方案:使用Firebase Analytics或自建SDK采集用户行为事件
实时数据处理
| 场景类型 | 技术实现 | 价值体现 |
|---|---|---|
| 位置服务 | Android定位API+Flink geo-fencing | 实时交通流量预测 |
| 推送系统 | FCM信令通道+Redis消息队列 | 毫秒级消息触达 |
| 异常检测 | 本地特征提取+Spark MLlib模型 | 设备故障预警响应时间<200ms |
边缘计算优化
- 本地预处理:在安卓设备执行TensorFlow Lite模型进行数据过滤
- 分级存储策略:频繁访问数据缓存至SQLite,原始数据异步上传
- 带宽优化:使用Protobuf压缩数据包,减少40%传输体积
技术对比矩阵
| 维度 | 安卓开发 | 大数据开发 |
|---|---|---|
| 数据特征 | 结构化/半结构化(SQLite) | 非结构化/流式(Kafka) |
| 延迟要求 | <100ms(UI响应) | 批处理小时级/流处理毫秒级 |
| 计算模式 | 事件驱动(主线程Looper) | 分布式并行(MapReduce) |
| 存储规模 | GB级(移动设备存储) | PB级(Hadoop集群) |
| 更新频率 | 高频(用户交互实时响应) | 低频(ETL周期执行) |
常见问题解答
Q1:如何在安卓应用中实现大数据量的实时可视化?
A:采用三级渲染策略:

- 数据采样:使用Flink CEP模式检测关键事件
- 增量更新:通过WebSocket推送变化量而非全量数据
- 图形优化:采用OpenGL ES绘制折线图,复用Canvas缓冲区
Q2:大数据处理流程如何保障安卓设备数据隐私?
A:实施多层保护机制:

- 传输加密:TLS1.3+证书双向认证
- 数据脱敏:在SDK层进行哈希处理(如SHA-256)
- 访问控制:基于RBAC模型的Kafka Topic权限管理
- 审计追踪:使用Hudi记录数据变更历史
扩展思考:当安卓设备作为物联网边缘节点时,如何设计轻量级大数据预处理框架?建议考虑Netty+Quarkus组合实现嵌入式数据处理能力,配合Traefik实现服务发现



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22