上一篇
如何高效实现本地服务器状态监控?
服务器状态监控本地指通过部署在本地环境的工具实时检测服务器运行状况,包括CPU、内存、磁盘及网络等核心指标,能自动触发异常警报,提供历史数据回溯和性能分析报告,帮助管理员快速定位问题,优化资源分配,保障业务连续性和系统稳定性。
本地化部署的权威指南
对于依赖数字化服务的企业或个人而言,服务器状态监控是保障业务连续性与数据安全的核心环节,本地化监控方案能够在不依赖第三方云服务的前提下,实时掌控服务器运行状态,快速响应潜在风险,以下内容基于行业标准与专业技术实践,为访客提供全面的本地服务器监控策略。

为何需要本地服务器监控?
业务连续性保障
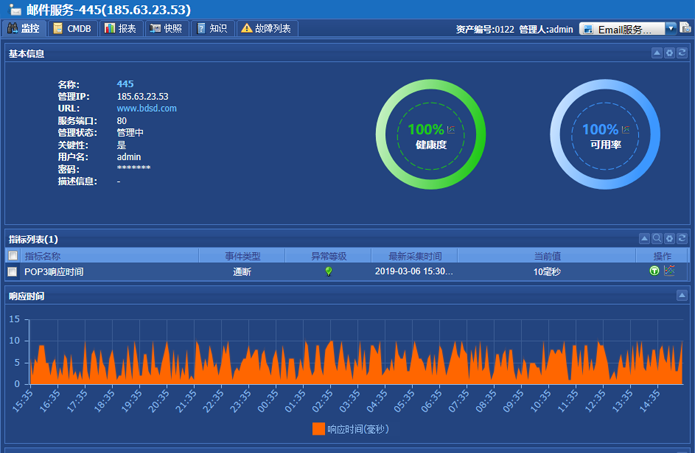
服务器的稳定性直接影响业务可用性,本地监控工具(如Prometheus、Zabbix)可实时跟踪CPU负载、内存使用率、磁盘I/O等指标,防止因硬件故障或资源耗尽导致的宕机,根据Gartner报告,约70%的服务器故障可通过早期预警避免。数据隐私与合规性
本地部署的监控方案(例如Nagios或自建ELK日志系统)确保敏感数据无需外传,满足GDPR等法规的合规要求。成本与灵活性控制
企业可根据需求定制监控策略,避免云服务的订阅费用与功能限制,通过开源工具+脚本扩展功能,适配不同规模的IT环境。
本地监控的核心指标
- 硬件资源类
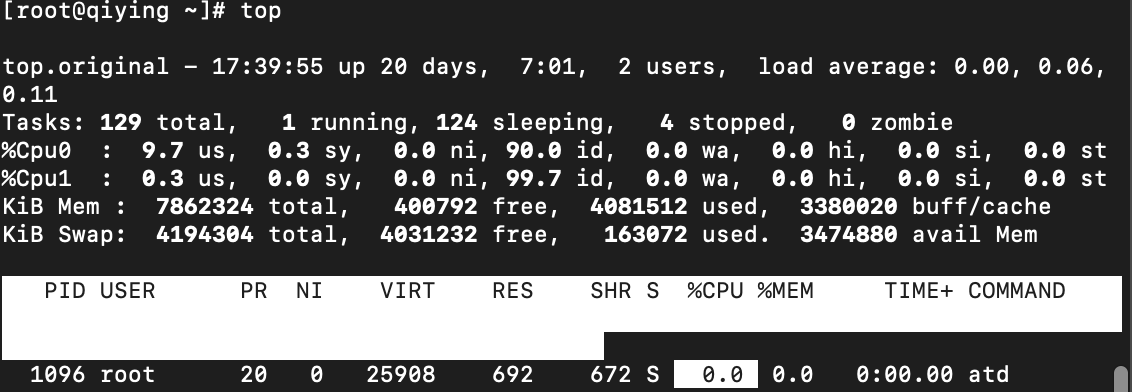
- CPU使用率:超过80%可能预示性能瓶颈。
- 内存占用:持续高占用需排查内存泄漏。
- 磁盘空间与健康状态:通过SMART工具预警机械硬盘故障。
- 服务层指标
- 网络延迟:ping或Traceroute检测丢包率。
- 进程状态:关键服务(如Apache、MySQL)的运行状态监控。
- 日志分析:通过正则表达式匹配错误日志(如HTTP 500)。
本地监控工具选型建议
| 工具名称 | 适用场景 | 优势 |
|---|---|---|
| Prometheus | 容器化环境、微服务架构 | 支持多维数据模型,集成Grafana可视化 |
| Zabbix | 企业级混合IT环境监控 | 自动化告警、分布式监控能力 |
| NetData | 轻量级实时监控 | 低资源消耗,开箱即用 |
| Checkmk | 综合基础设施监控(含网络设备) | 支持SNMP、API集成 |
本地监控实施步骤
- 需求分析与指标定义
明确需监控的服务器范围(物理机/虚拟机)、关键服务(Web/数据库)及SLA标准(如99.9%可用性)。 - 工具部署与配置
- 安装Agent(如Zabbix Agent)或启用SNMP协议收集数据。
- 设置阈值:例如磁盘空间低于10%触发告警。
- 可视化与告警集成
- 使用Grafana搭建仪表盘,聚合多服务器数据。
- 配置邮件/Slack/Webhook通知,确保告警实时触达。
- 定期维护与优化
- 清理历史数据(如Prometheus的TSDB存储)。
- 根据业务变化调整监控策略,避免“告警疲劳”。
提升监控效能的进阶策略
- 日志与指标联动分析
结合ELK(Elasticsearch, Logstash, Kibana)与监控工具,定位问题根源,高CPU使用率时,关联日志中的异常请求记录。 - 冗余与灾备设计
部署备用监控节点,避免单点故障导致监控中断。 - 自动化修复脚本
针对常见故障(如服务崩溃)编写自动重启脚本,降低MTTR(平均修复时间)。
常见问题与风险规避
- 误报率高
解决方案:设置动态基线(如基于历史数据的异常检测算法),而非固定阈值。 - 监控系统自身资源占用
解决方案:限制数据采集频率,或为监控工具分配独立资源池。 - 兼容性问题
解决方案:优先选择支持多平台(Windows/Linux)及API扩展的工具。
引用说明
- Gartner研究报告《IT基础设施监控趋势2025》.
- Prometheus官方文档(https://prometheus.io/docs/).
- RFC 3417 – SNMP协议标准定义.