接口cdn

在当今数字化时代,内容分发网络(CDN)已成为提升网络性能和用户体验的关键技术,CDN通过全球分布的边缘服务器缓存网站内容,使用户能够就近获取所需数据,从而显著提高访问速度和减少延迟,下面将深入探讨CDN接口的相关概念、类型、应用场景以及常见问题与解决方法:
CDN接口的基本概念
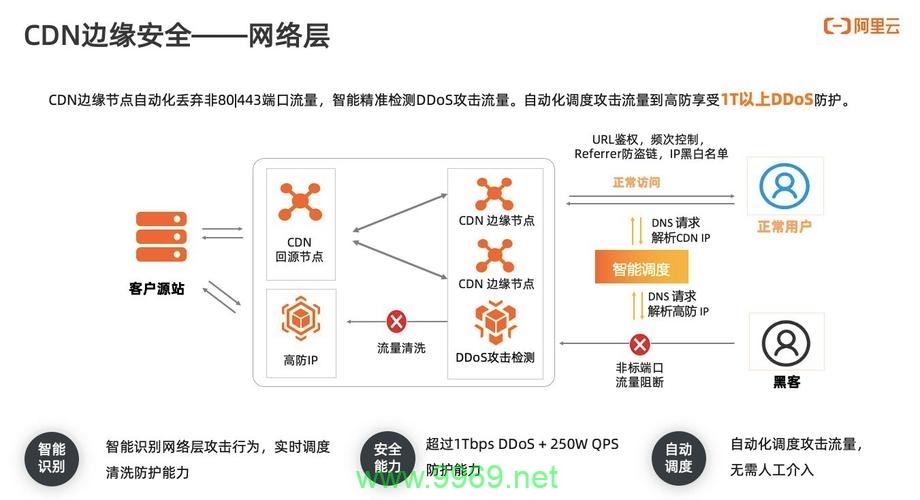
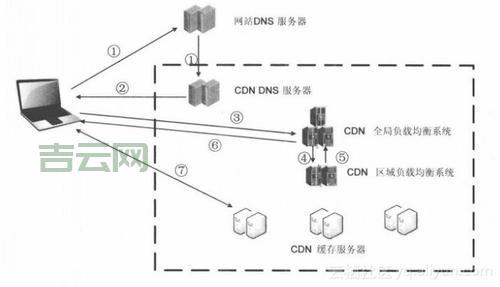
CDN接口是指CDN服务提供商为用户提供的用于接入和管理CDN服务的一系列应用程序编程接口(API),这些接口允许用户将自己的网站或应用与CDN网络进行集成,从而实现内容的快速分发和加速,通过CDN接口,用户可以配置缓存策略、管理缓存文件、监控CDN性能等,以优化内容分发效果。
CDN接口的类型
1、全站加速:对整个网站的所有内容进行加速处理,包括动态生成的内容和静态资源。
2、加速:针对动态生成的内容进行加速处理,如数据库查询结果、用户交互数据等。
3、加速:对静态资源如图片、CSS、JavaScript文件等进行加速处理。
CDN接口的应用场景
1、电商网站:在促销活动期间,大量用户同时访问网站,CDN可以显著提高网站的响应速度和稳定性。
2、视频网站:视频文件较大,通过CDN加速可以减少用户等待时间,提高观看体验。
3、社交网络:用户频繁地发布和获取动态信息,CDN加速可以提高这些操作的响应速度。
CDN接口的常见问题与解决方法
1、动态接口数据不一致
原因:由于CDN缓存机制,可能导致用户获取到过期的数据。
解决方法:设置合理的缓存过期时间;使用版本号或时间戳来标识数据的最新状态;对于实时性要求较高的数据,可以考虑不使用CDN加速,直接从源服务器获取。
2、CDN节点故障
原因:CDN节点可能由于硬件故障、网络问题等原因导致服务中断。
解决方法:部署多个CDN服务商,实现负载均衡和容灾备份;定期检查CDN节点的健康状态,及时发现并处理故障节点;使用智能DNS解析技术,将用户请求自动切换到可用的CDN节点。
CDN接口是提升网络性能和用户体验的重要工具,通过合理选择和使用CDN接口,网站和应用可以显著提高访问速度和稳定性,满足用户对快速、可靠内容分发的需求。