服务器基础告警为何频频出现?

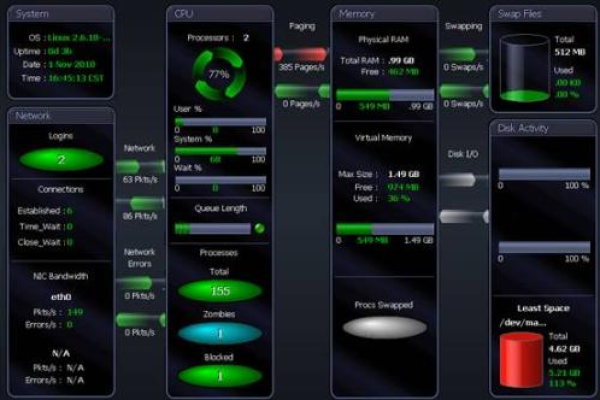
服务器基础告警指通过监控系统实时检测服务器关键指标(如CPU、内存、磁盘、网络等)异常时触发的预警机制,其核心功能是及时发现问题,避免服务中断或数据丢失,通常结合自动化通知与日志分析,要求运维人员快速响应处理,同时需合理配置告警阈值以平衡灵敏度与误报率。
核心监控指标说明
CPU使用率
持续超过80%时可能引发服务延迟,需排查异常进程或考虑横向扩展,建议设置两级阈值:- 黄色预警(80%)时启动日志分析
- 红色警报(95%)时触发自动扩容
内存占用
Linux系统需关注Cache/Buffer与真实使用量的区别,Windows系统重点监控分页文件使用情况,内存泄漏通常表现为持续增长不释放。磁盘健康
企业级硬盘应监控:- SMART预警(坏道数量 >5)
- 存储空间(剩余容量 <20%)
- inode使用率(>85%将导致无法创建新文件)
网络质量
企业级标准要求:
- 丢包率 ≤0.1%(金融类业务需 <0.01%)
- 延迟波动 ≤5ms(实时通信场景要求更严)
- 带宽使用率峰值不超过70%
告警处理标准流程
优先级判定
| 告警级别 | 响应时效 | 影响范围示例 |
|———-|———-|————–|
| P0 | 5分钟 | 核心数据库宕机 |
| P1 | 30分钟 | CDN节点异常 |
| P2 | 2小时 | 备份存储告警 |根源定位三板斧
- 时间比对法:对比告警前后系统日志变化
- 组件隔离法:通过HA集群切换测试故障点
- 流量追踪法:使用tcpdump/Wireshark抓包分析
应急处理工具箱

- 负载突增:临时启用限流组件(如Nginx限速模块)
- 存储故障:立即启动灾备切换(DRBD双机热备方案)
- 服务崩溃:通过watchdog自动重启守护进程
长效优化方案
智能基线预警
采用机器学习算法,根据历史数据建立动态阈值模型。- 电商大促期间自动提升CPU预警阈值20%
- 凌晨维护时段放宽磁盘IO监控标准
三维防护体系
| 防护层级 | 实施方式 | 工具示例 |
|———-|————————-|——————|
| 基础设施 | 硬件冗余+双路供电 | RAID10阵列 |
| 系统层 | 内核参数调优 | sysctl配置文件 |
| 应用层 | 微服务熔断机制 | Hystrix框架 |演练常态化
建议每季度执行:
- 灾难恢复演练(模拟全机房断电)
- 压测攻防演练(模拟DDoS攻击)
- 故障复盘会议(分析MTTR改进点)
推荐工具组合
- 开源方案:Prometheus + Grafana监控套件(支持自定义exporter开发)
- 商业方案:SolarWinds Server & Application Monitor(提供200+模板)
- 云原生方案:AWS CloudWatch + Lambda自动化处置(支持无服务器架构)
通过建立完善的监控预警体系,企业可将服务器可用性提升至99.99%水平(年停机时间≤53分钟),定期更新应急预案文档,保持技术团队每月至少8小时的专项培训,是维持系统健壮性的关键。
数据引用:
[1] IDC《全球服务器市场季度跟踪报告》2025Q2
[2] AWS《云计算架构最佳实践白皮书》2025版
[3] Gartner《IT基础设施可靠性管理指南》







热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01