cdn歌

CDN,全称为Content Delivery Network,即内容分发网络,以下是关于CDN的详细解释:
1、基本概念
CDN是一种利用分布式节点技术,在全球部署服务器的网络架构,它的核心作用是将网站、应用视频、音频等静态或动态资源内容分发到用户所在的最近节点,从而提高用户访问这些内容的速度和稳定性,降低网络拥塞和延迟,同时也能减轻源站的压力。
2、工作原理
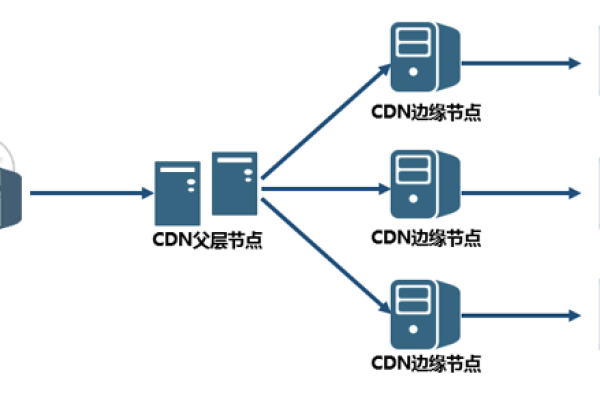
内容分发:CDN将源站的内容复制到不同区域的目标节点上,当用户请求访问时,通过全局负载技术将用户的请求指向距离最近的缓存服务器上,由缓存服务器响应用户的请求。
智能路由:CDN使用智能DNS解析技术,根据用户的位置和网络条件来选择最优的边缘服务器,确保用户能够通过最快的路径获取内容。
负载均衡:CDN通过在多个边缘服务器之间均匀分配用户请求的流量,实现负载均衡和高可用性。
3、系统组成
源服务器:存储网站内容的主要服务器,存放原始的网页、图像、视频和其他静态或动态文件。
边缘服务器:部署在全球各个地点的服务器节点,负责提供内容的分发和加速。
负载均衡器:用于在多个边缘服务器之间均匀分配用户请求的流量。
缓存机制:存储源服务器上的内容副本,减少对源服务器的负载,提高响应速度和用户体验。

DNS系统:解析用户请求的域名并将其映射到最近的边缘服务器。
4、优势特点
加速访问速度:通过在全球范围内部署服务器,使用户能够从距离更近的服务器获取内容,减少网络延迟,提高访问速度。
负载均衡:自动将请求分发到最优的服务器,实现负载均衡,提高服务的稳定性和可靠性。
减轻源服务器压力:缓存大量的静态资源,并在用户请求时直接返回,减轻了源服务器的负担。
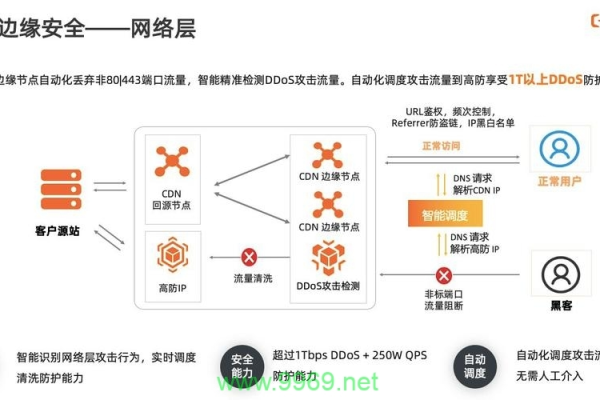
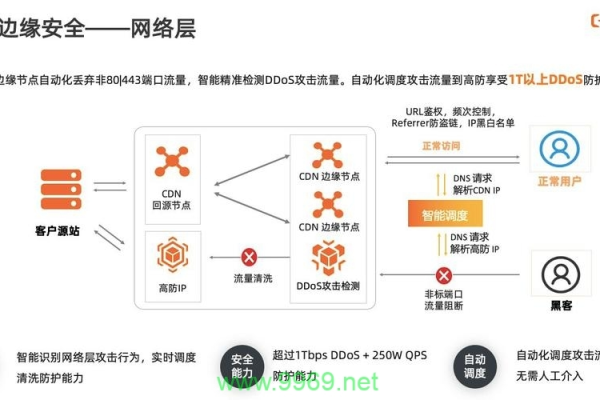
安全防护:提供DDoS攻击防护、源站防护等安全机制,保障网站的安全。
5、适用场景
加速:适用于网站、博客、在线商店等,将静态内容如图片、CSS、JavaScript文件等缓存到边缘节点,提高页面加载速度。

加速:适用于社交平台、新闻网站、在线教育平台等,通过智能路由和缓存策略优化动态内容的加载速度。
视频点播和直播:适用于视频平台、在线教育、体育赛事直播等,确保视频的流畅播放。
文件下载加速:适用于软件下载、游戏资源下载、企业文件共享等,提高下载速度和成功率。
安全防护:适用于所有需要保护的网站和应用,提供DDoS防护、WAF(Web应用防火墙)、SSL/TLS加密等安全功能。
6、性能优化
压缩技术:对传输的内容进行压缩,减少传输量,加快页面加载速度。
静态与动态内容处理:不仅能够高效分发静态文件,还能够处理动态内容,比如API调用。
7、实施步骤

选择CDN提供商:选择一个合适的CDN服务提供商,如阿里云CDN、酷盾安全(kdun.cn)CDN、AWS CloudFront、Cloudflare等。
配置源站:在CDN控制台中指定原始服务器的地址,并设置回源方式。
添加加速域名:将域名DNS解析中的CNAME记录指向CDN提供的加速域名。
配置缓存规则:定义哪些类型的文件应该被缓存以及缓存的时间长度。
配置安全设置:启用HTTPS协议,设置IP黑白名单、防盗链等功能以增加安全性。
测试配置:检查配置是否正确无误,并通过浏览器或其他工具测试访问情况。
监控与优化:利用CDN提供的监控工具定期查看网站的访问速度、流量等指标,并根据监控结果调整缓存策略、安全设置等。
CDN通过全球分布的边缘节点、高效的内容缓存机制、智能的路由算法以及强大的安全措施,实现了高效、快速、安全的内容分发,它在多种场景下都能提供显著的优势,包括提高内容分发效率、降低延迟、提升用户体验、增强安全性和支持大规模并发访问,选择合适的CDN服务和配置策略,可以帮助企业和个人更好地应对各种网络挑战。




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22