服务器内存持续飙升,你的系统扛得住吗?

服务器内存持续增长可能由内存泄漏、资源未释放或缓存过度堆积导致,常见于程序缺陷、高并发请求或配置不合理,需通过监控工具分析内存分配,定位异常进程,优化代码逻辑,及时释放闲置资源,必要时调整JVM参数或扩容硬件,防止系统崩溃。
服务器内存一直增长?可能是这些原因在“偷”内存
服务器内存持续增长是运维人员常遇到的棘手问题,若不及时处理可能导致应用崩溃、响应延迟甚至服务中断,本文将从排查思路、常见原因及解决方案入手,帮助你精准定位问题并高效修复。
内存持续增长的常见原因
内存泄漏(Memory Leak)
- 现象:应用长时间运行后,内存逐步被占用且不释放,最终耗尽系统资源。
- 常见场景:
- 代码中未正确关闭数据库连接、文件句柄或网络请求。
- 缓存未设置过期时间,数据无限堆积。
- 第三方库或框架存在缺陷(如Java的
ThreadLocal未清理)。
缓存设计不合理
- 缓存策略过于激进(如全量缓存),未考虑内存容量限制。
- 缓存淘汰机制缺失,旧数据无法及时清理。
资源未释放

- 未及时释放大对象(如日志文件、临时数据)。
- 线程池配置不当,线程堆积导致内存占用。
外部因素干扰
- 反面攻击导致请求量激增(如DDoS)。
- 系统或中间件(如MySQL、Redis)自身的内存分配问题。
排查内存问题的步骤与方法
定位内存消耗来源
- 通过系统命令初步分析
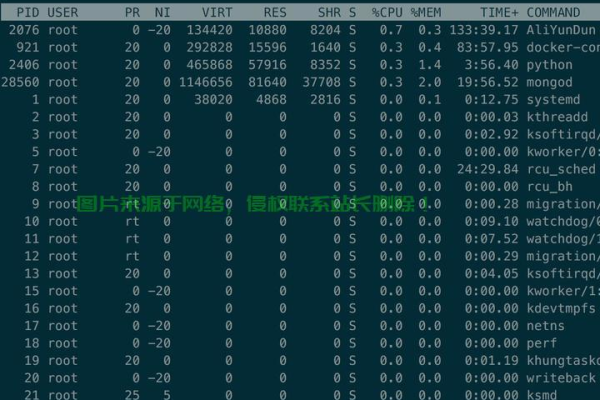
top或htop:查看进程的实时内存占用(重点关注RES和%MEM)。free -h:观察系统总内存使用情况,判断是否被缓存(Cache/Buffer)占用。
- 借助专业工具深入检测
- Java应用:使用
jstat分析堆内存,或用jmap生成堆转储文件(Heap Dump),通过MAT工具查看对象引用链。 - C/C++程序:使用Valgrind检测内存泄漏。
- Python应用:通过
tracemalloc或objgraph追踪对象分配。
- Java应用:使用
检查代码与配置
- 代码层面:
- 检查是否有死循环、递归调用未终止。
- 确保资源使用后显式释放(如调用
close()方法)。
- 配置层面:
- JVM参数是否合理(如
-Xmx堆大小设置过小可能引发频繁GC,反而增加内存压力)。 - 检查数据库连接池配置,防止连接数过多。
- JVM参数是否合理(如
监控与日志分析
- 部署监控系统:
- 使用Prometheus + Grafana实时监控内存趋势。
- 对关键指标(如堆内存使用率、线程数)设置报警阈值。
- 日志分析:
- 搜索错误日志中的
OutOfMemoryError或MemoryError关键词。 - 分析GC日志(如Java的
-XX:+PrintGCDetails),观察Full GC频率是否异常。
- 搜索错误日志中的
针对性解决方案
修复内存泄漏
- 使用弱引用(Weak Reference)替代强引用管理缓存。
- 确保所有资源使用
try-with-resources(Java)或with语句(Python)自动释放。
优化缓存策略

- 引入LRU(最近最少使用)淘汰算法,限制缓存容量。
- 使用分布式缓存(如Redis)分担内存压力。
调整系统参数
- 增加物理内存或优化虚拟内存(Swap)配置。
- 调整JVM的垃圾回收器(如G1GC替代Parallel GC)。
防御性措施
- 部署限流器(如Sentinel)防止突发流量压垮服务。
- 定期进行压力测试,模拟高并发场景下的内存表现。
预防内存问题的建议
代码规范与审查

- 强制代码Review,避免显式内存操作错误。
- 使用静态代码分析工具(如SonarQube)提前发现问题。
常态化监控
- 对生产环境建立基线指标(如正常内存水位线)。
- 定期巡检,结合APM工具(如Arthas)动态诊断。
依赖组件管理
- 及时升级中间件版本,修复已知内存破绽。
- 谨慎引入第三方库,优先选择经过验证的稳定版本。
引用说明
- 内存分析工具:Valgrind官方文档、Oracle JVM Troubleshooting Guide。
- 缓存优化策略:《Designing Data-Intensive Applications》Martin Kleppmann。




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01