
上一篇
Spark SQL如何实现跨数据库显示临时表,并先查ID再查数据库?
在 MySQL 中,你可以先通过 SELECT 语句查询 ID,再根据该 ID 查询数据库。而在 Spark SQL 中,你可以在不同的数据库上显示临时表,这为跨数据库的数据处理提供了便利。
在现代数据管理和分析领域,MySQL和Spark SQL是两种非常流行的技术,本文将详细探讨如何在MySQL中先查ID再查数据库,以及Spark SQL在不同数据库中显示临时表的机制。

一、MySQL中先查ID再查数据库
在MySQL中,先查ID再查数据库是一种常见的操作模式,特别是在需要根据特定条件筛选数据时,以下是一个详细的步骤说明:
1、创建测试环境:
假设我们有一个名为users的表,其中包含以下列:id(用户ID)、name(用户名)和email(电子邮件)。
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);2、插入测试数据:
INSERT INTO users (id, name, email) VALUES (1, 'Alice', 'alice@example.com'), (2, 'Bob', 'bob@example.com'), (3, 'Charlie', 'charlie@example.com');
3、先查ID再查数据库:
我们可以先查询某个用户的ID,然后再根据这个ID查询用户的详细信息,查找ID为2的用户信息:
SELECT * FROM users WHERE id = 2;结果将是:
+----+-------+-------------------+
| id | name | email |
+----+-------+-------------------+
| 2 | Bob | bob@example.com |
+----+-------+-------------------+这种操作模式在实际应用中非常有用,特别是在需要根据动态条件筛选数据时,在电商网站中,可以根据商品ID查询商品详情,或者在社交网络中根据用户ID查询用户资料。
二、Spark SQL在不同DB都可以显示临时表
Spark SQL允许在不同的数据库中显示临时表,这为数据分析提供了极大的灵活性,以下是Spark SQL在不同数据库中显示临时表的详细说明:
1、临时表的概念:
临时表是在会话期间存在的表,当会话结束时,临时表会自动删除,Spark SQL支持三种层次的同名数据表:Spark的临时表、当前DB的Hive临时表和当前DB的Hive持久化表。
2、查询优先级:
当执行查询时,Spark SQL会优先查看是否有Spark的临时表,如果没有,再查找当前DB的Hive临时表,最后查找当前DB的Hive持久化表。
3、使用示例:
假设我们在Spark会话中创建了一个临时表temp_table,并插入了一些数据:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("example").getOrCreate()
df = spark.createDataFrame([(1, 'Alice'), (2, 'Bob'), (3, 'Charlie')], ['id', 'name'])
df.createOrReplaceTempView('temp_table')然后我们可以查询这个临时表:
SELECT * FROM temp_table;结果将是:
+---+------+
| id| name|
+---+------+
| 1| Alice|
| 2| Bob|
| 3|Charlie|
+---+------+MySQL中的先查ID再查数据库的操作模式和Spark SQL在不同数据库中显示临时表的机制,都是现代数据管理和分析中的重要技术,通过合理利用这些技术,可以大大提高数据处理的效率和灵活性。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/388902.html
相关文章
-
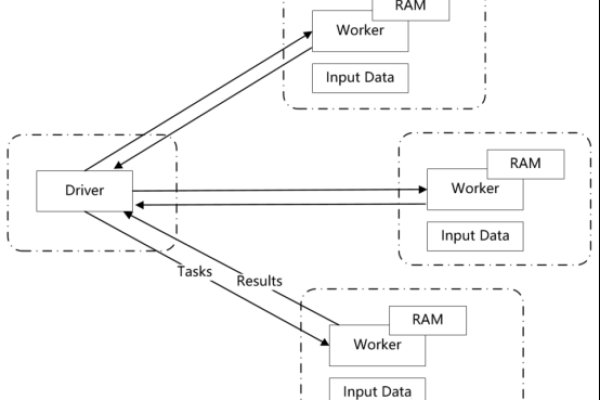
在分布式计算领域,MapReduce和Spark作为两种流行的大数据处理框架,它们在设计哲学、性能优化以及易用性方面存在显著差异。特别是当涉及到华为云的DLI(数据湖探索)服务中的Spark组件与华为云MRS(MapReduce服务)中的Spark组件时,用户可能会好奇这两者之间的具体区别是什么?
-
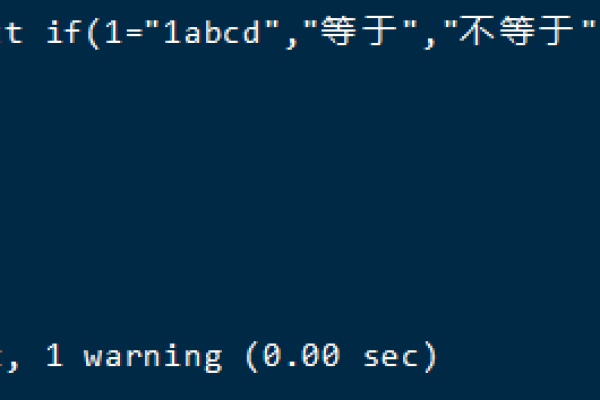
在编写关于MySQL和Spark SQL中ROLLUP与CUBE操作的注意事项时,一个原创的疑问句标题可以是,,在使用MySQL和Spark SQL进行数据聚合时,如何正确应用ROLLUP和CUBE功能以避免常见错误?
-

存储过程创建临时表 索引_临时表
-

磁盘临时表_临时表
-
如何在MySQL数据库服务中处理Spark作业结果,并在缺少pymysql模块的情况下使用Python脚本访问MySQL数据库?
-
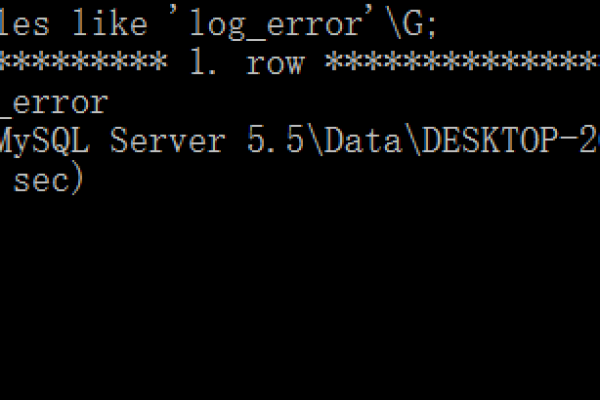
如何实现MySQL中跨数据库服务器查询并检查数据库错误日志?
-
pymysql连接mysql_将Spark作业结果存储在MySQL数据库中,缺少pymysql模块,如何使用python脚本访问MySQL数据库?
-
aspnet 临时数据库_临时表
-
什么是MySQL中的临时表,它们如何工作?








