服务器突发故障如何快速解决?

当服务器出现异常时,应首先检查系统日志定位问题根源,及时备份关键数据防止丢失,根据故障类型采取对应措施,如硬件故障需替换部件,网络攻击需启用防火墙拦截,资源过载则优化程序或扩容,必要时回滚到稳定版本,并建立监控预警机制预防同类问题发生。
当服务器出现异常情况时,用户访问网站可能会遇到页面加载失败、数据丢失或功能异常等问题,这不仅影响用户体验,还可能对业务造成损失,以下是一套系统化的解决方案,结合技术操作与预防措施,确保服务器稳定运行。
服务器常见问题分类与应对策略
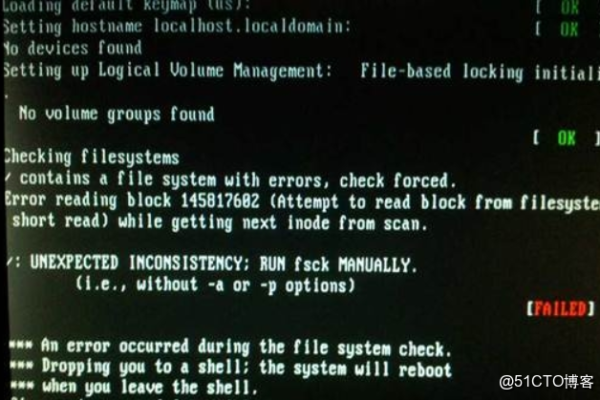
服务器宕机或无法访问
- 现象:网站无法打开、请求超时。
- 解决步骤:
- ① 检查服务器状态:通过云服务商控制台(如阿里云ECS、AWS EC2)确认服务器是否处于“运行中”状态。
- ② 排查网络问题:使用
ping、traceroute命令测试连通性;检查防火墙规则是否误拦截流量。 - ③ 重启服务器:若资源占用过高(如CPU或内存爆满),尝试重启释放资源。
- ④ 联系服务商:如果是硬件故障(如硬盘损坏),需立即提交工单申请更换。
网站响应缓慢
- 现象:页面加载时间超过3秒,用户流失率上升。
- 解决步骤:
- ① 性能监控:使用工具(如New Relic、Prometheus)定位瓶颈,检查数据库查询、API响应时间或代码逻辑。
- ② 优化资源:压缩图片/JS/CSS文件;启用CDN加速静态资源;升级服务器配置。
- ③ 数据库调优:增加索引、清理冗余数据,或切换为读写分离架构。
遭受反面攻击
- 现象:流量激增、IP被封禁、出现未知进程。
- 解决步骤:
- ① 隔离服务器:临时关闭非必要端口,阻断可疑IP(通过防火墙或安全组)。
- ② 分析日志:使用
awk或grep分析访问日志,识别攻击类型(如DDoS、SQL注入)。 - ③ 启用防护:部署Web应用防火墙(WAF),或接入云服务商的高防IP。
- ④ 数据备份恢复:若系统被载入,从干净的备份中还原数据。
预防性维护:降低服务器风险的核心方法
定期备份与容灾

- 使用自动化工具(如rsync、BorgBase)每天备份关键数据,并存储到异地服务器或对象存储(如AWS S3)。
- 建立多区域容灾架构,例如通过负载均衡将流量分发至多个可用区。
实时监控与告警

- 部署监控系统(Zabbix、Nagios),设定CPU、内存、磁盘使用率阈值,触发告警通知运维人员。
- 对关键服务(如MySQL、Nginx)设置健康检查,自动重启失败进程。
安全加固
- 强制使用SSH密钥登录,禁用root账户;定期更新系统补丁与软件版本。
- 限制数据库权限,避免使用默认端口(如将MySQL端口从3306改为非标端口)。
性能压测与预案

- 通过JMeter或LoadRunner模拟高并发场景,提前优化代码和资源配置。
- 编写应急预案,明确故障时的分工与操作流程(例如切换备用DNS解析)。
何时需要寻求专业支持?
- 复杂攻击处理:若遭遇APT攻击(高级持续性威胁),需联系网络安全公司进行深度取证。
- 数据恢复失败:当备份文件损坏或误删除重要数据时,可使用专业工具(如R-Studio)或第三方恢复服务。
- 硬件级故障:如服务器主板损坏,需由云服务商或IDC机房技术人员协助更换。
引用说明
- 服务器运维实践参考自AWS官方文档《Best Practices for EC2》(2025)。
- 安全防护建议部分内容来源于OWASP《Web应用安全指南》。
- 性能优化案例引自阿里云《云服务器ECS故障排查手册》。




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22