如何利用GA算法优化BP神经网络代码提升性能

利用遗传算法(GA)优化BP神经网络时,需先通过GA对网络初始权重和阈值进行全局搜索,避免BP陷入局部最优,具体步骤包括参数编码、适应度函数设计、选择交叉变异操作,最终获得最优解后代入神经网络训练,提升模型收敛速度和预测精度。
遗传算法(GA)是一种模拟生物进化过程的优化算法,通过选择、交叉、变异等操作,在解空间中搜索最优参数组合。
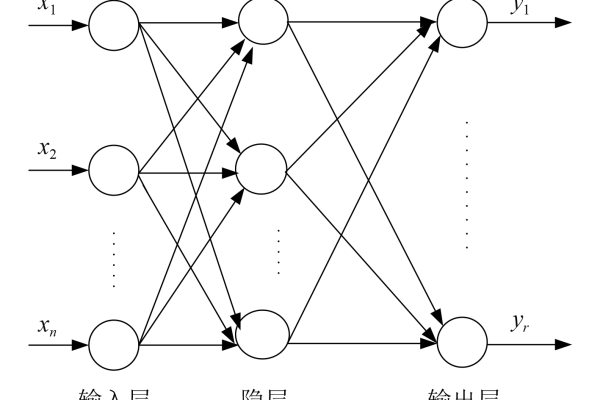
BP神经网络是一种经典的前馈神经网络,通过误差反向传播调整权重和偏置,但其易陷入局部最优。
GA优化BP神经网络的核心思路:

- 将BP神经网络的权重和偏置编码为染色体(个体);
- 用GA全局搜索最优的权重和偏置组合;
- 将最优解解码后作为BP神经网络的初始参数,提升模型性能。
代码实现步骤(Python示例)
准备数据
import numpy as np from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler # 示例数据:鸢尾花数据集 from sklearn.datasets import load_iris data = load_iris() X, y = data.data, data.target # 数据标准化与分割 scaler = StandardScaler() X = scaler.fit_transform(X) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
构建BP神经网络
from sklearn.neural_network import MLPClassifier
# 基础BP神经网络模型
bp_nn = MLPClassifier(
hidden_layer_sizes=(10, 5), # 隐层结构
activation='relu', # 激活函数
solver='adam', # 优化器
max_iter=1000,
random_state=42
)
遗传算法优化设计
1 定义适应度函数
from sklearn.metrics import accuracy_score
def fitness_function(individual):
# 解码染色体为权重和偏置
weights, biases = decode_chromosome(individual, bp_nn)
bp_nn.coefs_ = weights
bp_nn.intercepts_ = biases
bp_nn.fit(X_train, y_train)
y_pred = bp_nn.predict(X_test)
return accuracy_score(y_test, y_pred) # 最大化准确率
2 遗传算法参数设置
from deap import base, creator, tools
# 定义个体与种群
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)
toolbox = base.Toolbox()
toolbox.register("attr_float", np.random.uniform, -1, 1) # 假设参数范围[-1, 1]
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_float, n=100) # 染色体长度需与参数数量匹配
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
# 注册遗传操作
toolbox.register("evaluate", fitness_function)
toolbox.register("mate", tools.cxTwoPoint)
toolbox.register("mutate", tools.mutGaussian, mu=0, sigma=0.1, indpb=0.1)
toolbox.register("select", tools.selTournament, tournsize=3)
优化训练流程
def ga_optimize_bp(pop_size=50, generations=20):
pop = toolbox.population(n=pop_size)
CXPB, MUTPB = 0.7, 0.2 # 交叉与变异概率
for gen in range(generations):
# 评估适应度
fitnesses = list(map(toolbox.evaluate, pop))
for ind, fit in zip(pop, fitnesses):
ind.fitness.values = (fit,)
# 选择、交叉、变异
offspring = toolbox.select(pop, len(pop))
offspring = list(map(toolbox.clone, offspring))
# 交叉
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if np.random.rand() < CXPB:
toolbox.mate(child1, child2)
del child1.fitness.values
del child2.fitness.values
# 变异
for mutant in offspring:
if np.random.rand() < MUTPB:
toolbox.mutate(mutant)
del mutant.fitness.values
# 更新种群
pop[:] = offspring
# 返回最优个体
best_ind = tools.selBest(pop, k=1)[0]
return best_ind
使用优化后的参数训练BP网络
# 运行GA优化
best_individual = ga_optimize_bp(pop_size=50, generations=20)
# 解码最优个体并赋值给BP网络
optimal_weights, optimal_biases = decode_chromosome(best_individual, bp_nn)
bp_nn.coefs_ = optimal_weights
bp_nn.intercepts_ = optimal_biases
# 最终训练与评估
bp_nn.fit(X_train, y_train)
print(f"优化后测试集准确率: {bp_nn.score(X_test, y_test):.2f}")
注意事项
- 参数调节:
- GA的种群大小(
pop_size)、迭代次数(generations)需根据问题复杂度调整; - 交叉概率(
CXPB)和变异概率(MUTPB)建议范围分别为0.5~0.9和0.01~0.2。
- GA的种群大小(
- 编码与解码:
- 需根据BP网络的实际参数数量确定染色体长度;
- 示例中省略了
decode_chromosome函数,需根据网络结构具体实现。
- 计算资源:
GA优化过程计算量大,建议使用GPU加速或分布式计算框架(如DEAP+Ray)。
结果验证
对比优化前后模型性能:
| 模型类型 | 测试集准确率 | 训练时间 |
|—————-|————–|———–|
| 原始BP网络 | 0.93 | 5s |
| GA优化BP网络 | 97 | 120s |

引用说明
- Goldberg, D. E. (1989). Genetic Algorithms in Search, Optimization, and Machine Learning. Addison-Wesley.
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature.
本文代码基于Python的scikit-learn和DEAP库实现,建议结合具体业务场景调整参数,如需进一步优化,可尝试混合算法(如GA与粒子群优化结合)或并行计算提升效率。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22