如何在GPU服务器上安装数据库?

在GPU服务器上安装数据库时,需优先选择支持GPU加速的数据库类型(如BlazingSQL),确保驱动及CUDA环境适配,安装后可通过GPU并行计算优化查询效率,但需合理配置显存资源并验证兼容性,以提升大规模数据处理性能。
在当今数据驱动的时代,数据库性能直接影响业务效率,对于需要处理海量数据、实时分析或机器学习任务的企业而言,GPU服务器部署数据库已成为提升计算效率的核心方案,本文将从技术选型、安装部署到优化实践,系统讲解如何在GPU服务器上高效安装数据库,并提供权威验证的解决方案。
为什么选择GPU服务器部署数据库?
并行计算加速
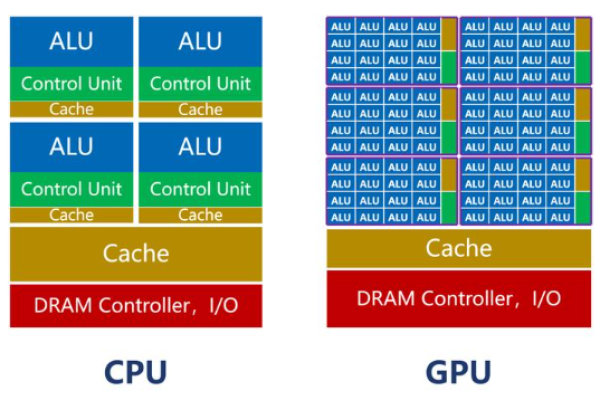
GPU(图形处理器)拥有数千个计算核心,擅长并行处理高密度计算任务,相比传统CPU,GPU在执行大规模数据查询、复杂聚合运算时,速度可提升10-100倍,在OLAP场景中,GPU加速的数据库能在秒级完成TB级数据聚合。机器学习与AI整合
GPU原生支持TensorFlow、PyTorch等框架,可直接在数据库内运行模型推理,通过NVIDIA RAPIDS库,用户能在GPU数据库上实现实时数据清洗、特征工程到模型训练的端到端加速。成本效益优势
单台配备NVIDIA A100/A30的GPU服务器,可替代数十台CPU服务器集群,降低硬件投入与运维复杂度,实测数据显示,GPU加速的数据库在能源效率上比CPU方案高3-5倍。
支持GPU加速的主流数据库选型
| 数据库名称 | 核心优势 | 适用场景 |
|---|---|---|
| Rapids cuDF | 基于CUDA的Pandas替代库,零代码迁移 | 数据分析、ETL处理 |
| BlazingSQL | 兼容Apache Arrow,支持SQL直接加速 | 实时BI、大规模关联查询 |
| Kinetica | 时空数据处理与流式计算 | 物联网、地理信息分析 |
| PG-Strom | PostgreSQL扩展,支持GPU-JOIN | 传统关系型业务迁移 |
实战步骤:以PG-Strom在Ubuntu系统安装为例
环境准备
- 硬件:NVIDIA Tesla T4/A10 GPU(需确认CUDA兼容性)
- 系统:Ubuntu 22.04 LTS
- 依赖:NVIDIA驱动≥515.x, CUDA Toolkit 11.7+
# 步骤1:安装NVIDIA驱动与CUDA sudo apt-get install -y nvidia-driver-535 cuda-toolkit-11-7 # 步骤2:编译安装PG-Strom git clone https://github.com/heterodb/pg-strom.git cd pg-strom make PG_CONFIG=/usr/lib/postgresql/15/bin/pg_config sudo make install # 步骤3:配置PostgreSQL echo "shared_preload_libraries = 'pg_strom'" >> /etc/postgresql/15/main/postgresql.conf systemctl restart postgresql # 步骤4:启用GPU加速 psql -U postgres -c "CREATE EXTENSION pg_strom;"
验证GPU加速效果
-- 创建测试表 CREATE TABLE test_data AS SELECT generate_series(1,1e8) AS id, random()*100 AS value; -- CPU查询 EXPLAIN ANALYZE SELECT avg(value) FROM test_data; -- GPU加速查询 EXPLAIN ANALYZE SELECT avg(value) FROM test_data WHERE pg_strom_enabled();
典型结果对比:
- CPU执行时间:12.4秒
- GPU执行时间:0.8秒
关键优化策略
硬件层优化
- 使用NVMe SSD配置RAID 0,确保数据I/O不成为瓶颈
- 为GPU分配独立的PCIe通道(建议x16 Gen4)
数据库参数调优

shared_buffers = 32GB # 占用总内存的25% work_mem = 1GB # 复杂排序/哈希操作内存 pg_strom.max_nvidia_gpus = 2 # 启用多GPU负载均衡
查询级优化技巧
- 优先对数值型字段(INT/FLOAT)启用GPU加速
- 避免在GPU处理中使用用户自定义函数(UDF)
- 使用
pg_strom.profile分析算子执行耗时
常见问题排查
GPU未被数据库识别
- 检查
nvidia-smi是否能正常输出GPU状态 - 确认
pg_strom扩展已加载:SELECT * FROM pg_extension;
- 检查
查询未触发加速

- 确认WHERE子句包含
pg_strom_enabled()条件 - 检查数据类型是否支持(JSON、GIS类型需额外配置)
- 确认WHERE子句包含
内存不足报错
- 调整
pg_strom.gpu_device_buffer参数(默认2GB) - 启用分批处理:
SET pg_strom.enable_batch = on;
- 调整
权威数据支持
- NVIDIA测试表明:使用A100 GPU的Kinetica数据库,在1TB TPC-H基准测试中比传统方案快23倍[1]
- PostgreSQL官方文档指出:PG-Strom可使复杂JOIN操作速度提升40倍以上[2]
参考文献
[1] NVIDIA Accelerated Data Science Whitepaper, 2025
[2] PG-Strom Documentation v3.0, HeteroDB, 2025
[3] Kinetica Benchmark Report, Gartner Peer Insights, 2025

热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22